



In the present day, OpenAI rival Anthropic introduced Claude 4 fashions, that are considerably higher than Claude 3 in benchmarks, however we’re left disenchanted with the identical 200,000 context window restrict.
In a weblog publish, Anthropic stated Claude Opus 4 is the corporate’s strongest mannequin, and it is also the most effective mannequin for coding within the trade.
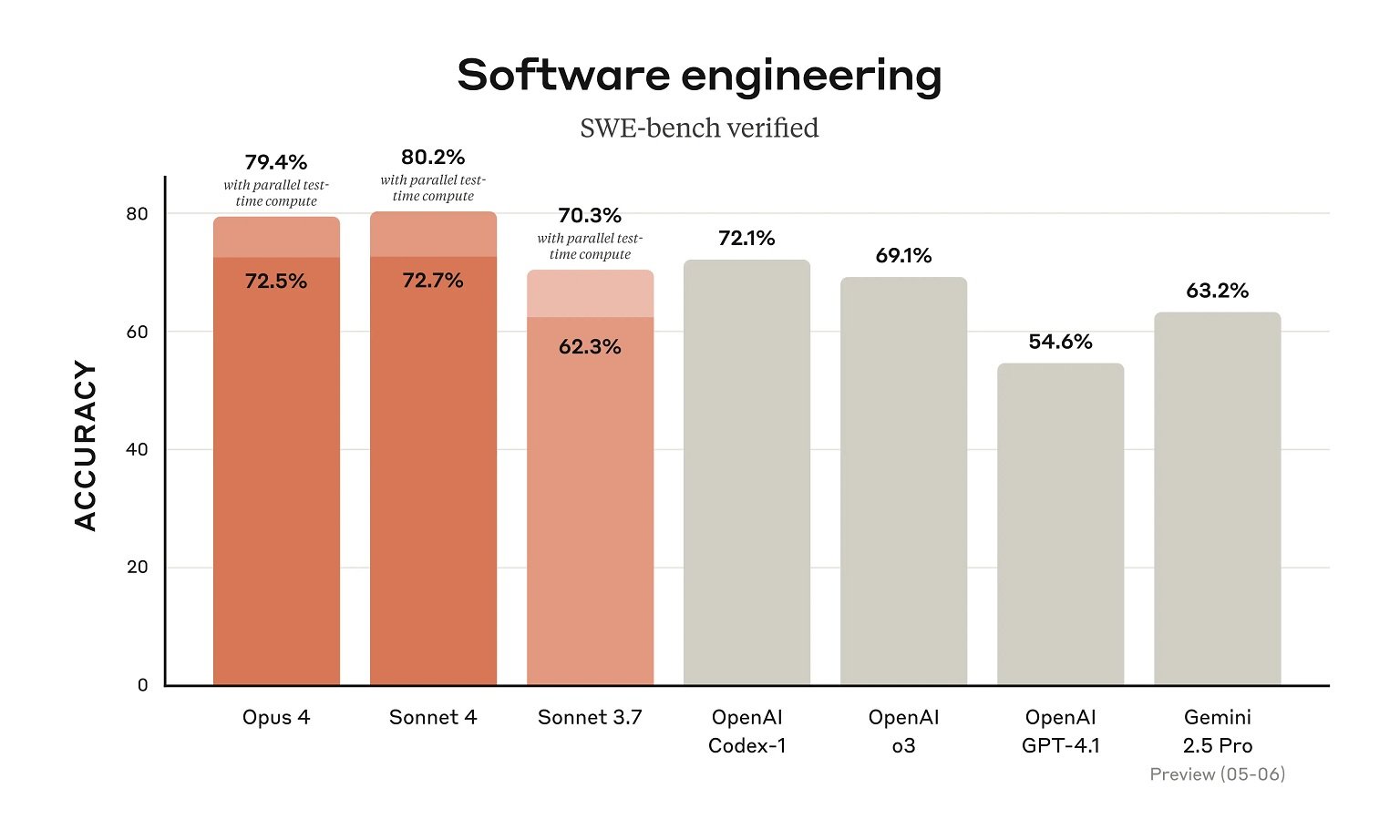
For instance, in SWE-bench (SWE is brief for Software program Engineering Benchmark), Claude Opus 4 scored 72.5 p.c and 43.2 on Terminal-bench.
“It delivers sustained efficiency on long-running duties that require targeted effort and hundreds of steps, with the flexibility to work repeatedly for a number of hours, dramatically outperforming all Sonnet fashions and considerably increasing what AI brokers can accomplish,” Anthropic famous.
Whereas benchmarks put Claude 4 Sonnet and Opus forward of their predecessors and opponents like Gemini 2.5 Professional in coding, we’re nonetheless involved concerning the mannequin’s 200,000 context window restrict.
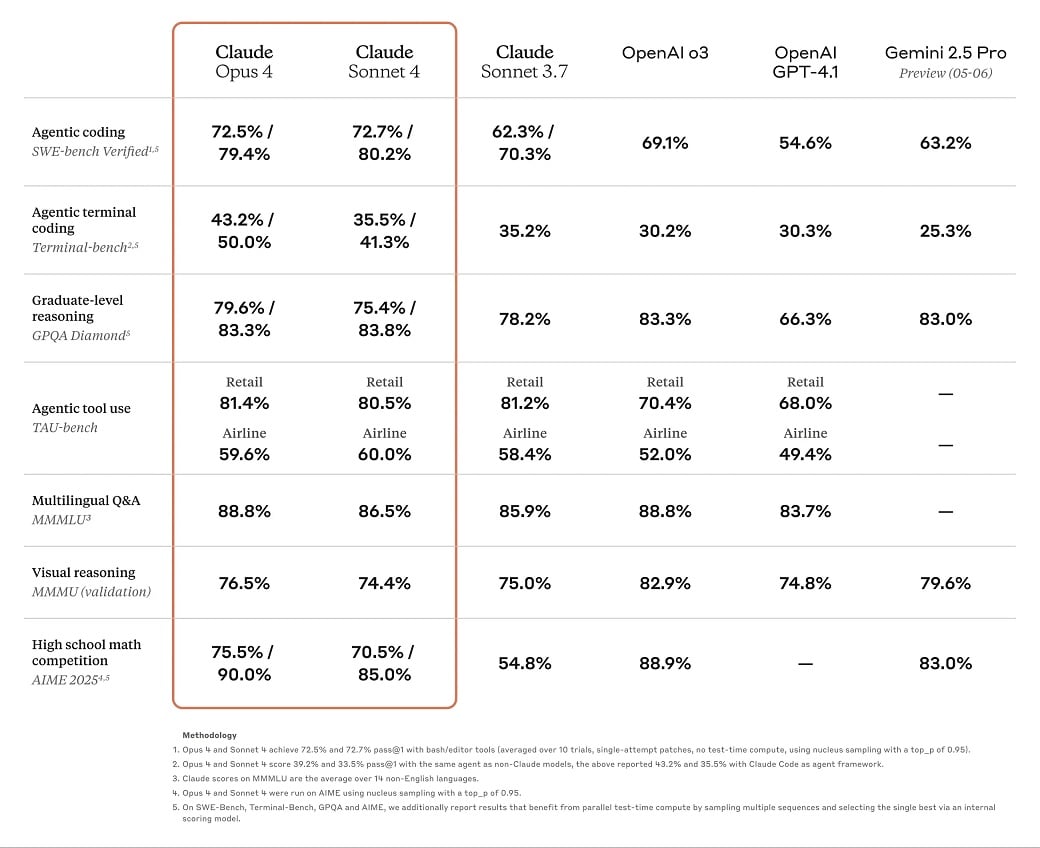
This might be one of many explanation why Claude 4 fashions excel at coding and complex-solving duties in these benchmarks, as a result of these fashions aren’t being examined towards a big context.
For comparability, Google’s Gemini 2.5 Professional ships with a 1 million token context window and help for a 2 million context window can also be within the works.
ChatGPT’s 4.1 fashions additionally provide as much as a million context window.
Mannequin
Description
Enter
Immediate Caching Write
Immediate Caching Learn
Output
Context Window
Batch Processing Low cost
Claude Opus 4
Most clever mannequin for complicated duties
$15 / MTok
$18.75 / MTok
$1.50 / MTok
$75 / MTok
200K
50% low cost with batch processing
Claude Sonnet 4
Optimum steadiness of intelligence, value, and pace
$3 / MTok
$3.75 / MTok
$0.30 / MTok
$15 / MTok
200K
50% low cost with batch processing
Claude remains to be lagging behind the competitors relating to the context window, which is essential in giant tasks.

Based mostly on an evaluation of 14M malicious actions, uncover the highest 10 MITRE ATT&CK methods behind 93% of assaults and how you can defend towards them.

{kind=link}