



Amazon Q generative SQL brings generative AI capabilities to assist pace up deriving insights out of your Amazon Redshift information warehouses and AWS Glue Information Catalog, producing SQL for Amazon Redshift or Amazon Athena. With Amazon Q, you get SQL instructions generated together with your context. This implies you possibly can deal with deriving insights quicker, slightly than having to first study doubtlessly advanced schemas. With out generative SQL, your information analysts may need to regularly change between various kinds of SQL, which may additional sluggish evaluation down. Amazon Q generative SQL will help by producing SQL statements from pure language and rushing up improvement. This will help onboard analysts quicker and enhance analyst productiveness. The generative SQL expertise is out there by Amazon SageMaker Unified Studio and Amazon Redshift Question Editor v2.
To scale the usage of generative SQL in manufacturing eventualities, you want to contemplate how related and correct SQL is generated. In doing so, it’s necessary to grasp what information is used and the way your data is protected. Amazon Q generative SQL is designed to maintain your information safe and personal. Your queries, information, and database schemas aren’t used to coach generative AI basis fashions (FMs). For extra data, see Concerns when interacting with Amazon Q generative SQL.
Within the submit Write queries quicker with Amazon Q generative SQL for Amazon Redshift, we supplied basic recommendation round getting began with generative SQL. On this submit, we talk about the design and safety controls in place when utilizing generative SQL and its use in each SageMaker Unified Studio and Amazon Redshift Question Editor v2.
Answer overview
Producing related SQL requires context out of your information warehouse or information catalog schemas. Your analysts can ask free textual content or pure language questions within the Amazon Q chat window and have SQL statements returned that reference your tables and columns. It’s necessary that the generated SQL is constant together with your schema in order that it will probably discover probably the most related fields to reply questions and generate queries that precisely reference information. In SageMaker Unified Studio or Amazon Redshift Question Editor v2, when the Amazon Q chat window is open, database metadata that’s viewable below the connection context is made accessible to Amazon Q for SQL technology. Because of this solely the schema data that the connecting person can entry is used. Tables or database objects the person doesn’t have entry to are excluded.
When a person submits questions within the Amazon Q chat window, a search algorithm is used to seek out probably the most related context from the accessible database schema metadata data. This context is mixed with the person’s query and used as a immediate to a big language mannequin (LLM) to generate a SQL assertion. The supporting data is cached in order that your information supply doesn’t should be queried each time a person initiates SQL technology. As a substitute, information supply metadata might be periodically refreshed if it stays in use, or you possibly can set off a guide refresh. If the info just isn’t getting used, Amazon Q will mechanically delete it. The place relevant, the data used to help SQL technology is encrypted with an AWS Key Administration Service (AWS KMS) buyer managed KMS key the place one has been specified within the SageMaker Unified Studio or Amazon Redshift Question Editor v2 settings. In any other case, an AWS managed secret is used. Your data is encrypted in transit and at relaxation.
The next diagram exhibits the method movement for SQL technology when utilizing SageMaker Unified Studio or the Amazon Redshift Question Editor and utilizing Amazon Redshift or Information Catalog supply information.
The Amazon Q generative SQL course of could be summarized as the next steps:
A person interacts with the Amazon Q chat pane by SageMaker Unified Studio or the Amazon Redshift Question Editor.
The SQL chat frontend sends the immediate together with the connection configuration to Amazon Q.
Amazon Q makes use of the connection context to retrieve data that can help SQL technology if this information just isn’t already accessible.
Amazon Q encrypts the retrieved data below the suitable AWS managed or buyer managed KMS key. The data is subsequently decrypted on retrieval.
The data is saved together with customized context data, if this has been supplied.
Related context from the mixed data is chosen and added to the person’s questions and despatched to an LLM to generate a SQL assertion, which is returned to the person.
The person can determine whether or not to run the assertion and might present suggestions on usefulness and accuracy.
Extra context to reinforce SQL technology
You may present additional context to complement the database schema data, which will help enhance the accuracy and relevancy of the generated SQL.
One possibility is to offer customized context. Customized context provides the choice to specify directions and further data, akin to descriptions of tables and columns. These descriptions can then be used to assist the choice of related tables and attributes when producing SQL statements. That is notably related when your schema makes use of extra obscure naming which may circuitously relate to enterprise phrases or makes use of non-standard abbreviations. For instance, contemplate a desk referred to as sls_r1_2024. With customized context, you possibly can add a desk description specifying that, for instance, the desk consists of gross sales data throughout shops within the US area for the calendar 12 months 2024. This data will help the LLM generate SQL referencing the right tables. The identical method could be utilized to columns throughout the desk. Your customized context is encrypted utilizing a buyer managed KMS key if one has been specified (throughout Amazon Redshift Question Editor account creation or SageMaker Unified Studio challenge creation) or an AWS managed key in any other case.
You can too introduce constraints utilizing customized context. For instance, you possibly can explicitly embrace or exclude particular schemas, tables, or columns from SQL question technology. Equally, particular matters will also be disallowed, akin to not producing SQL statements to help monetary reporting. For extra particulars in regards to the data that may be provided, confer with Customized context.
An alternative choice is to grant SQL question historical past entry to the person establishing the connection. This data is then additionally made accessible to reinforce SQL technology and to offer the LLM with examples of related queries. Bear in mind that granting wider SQL question historical past entry to the connecting person, and subsequently additionally the generative SQL workflow, permits viewing of queries over tables or objects the person may not have entry to. Moreover, string literals may be current in historic statements which may comprise delicate data. To assist mitigate this danger, you can as a substitute use the CuratedQueries part of customized context to offer predefined query and reply examples, with out exposing all person queries.
Generated assertion response
Earlier than a SQL assertion is returned to the person, Amazon Q tries to detect syntax points. This step helps enhance the probability that solely legitimate SQL syntax is returned. Amazon Q will use the accessible data for the person to return statements that align with person permissions, to cut back eventualities the place customers can’t run generated statements. For instance, when you’ve got given entry to SQL question historical past data, then the SQL technology step would possibly produce a question assertion referencing a desk that the person asking the query doesn’t have entry to. Amazon Q minimizes the prevalence of this state of affairs by assessing if the generated SQL aligns with person permissions and updating the assertion if not. Consumer permissions aren’t bypassed by the usage of Amazon Q generative SQL. If a press release was returned referencing a desk the person doesn’t have entry to, the authorization utilized to the person will implement entry management when the assertion is executed.
Statements generated by Amazon Q that would doubtlessly change your database, akin to DML or DDL statements, are returned with a warning. The warning highlights to the person that working the assertion may doubtlessly modify the database. Once more, these statements are solely executable if the person has the required permissions.
Conditions
Amazon Q generative SQL works together with your Redshift information warehouses and Information Catalog tables. To get began, it is best to have information accessible in both or each of those environments. To make use of Amazon Q generative SQL together with your AWS Glue tables, you want a SageMaker Unified Studio area. Inside your area, you should utilize the Amazon Q chat integration to ask questions of your information and have SQL generated. This additionally works for Amazon Redshift information sources accessible within the area. You should utilize Amazon Q generative SQL with out a SageMaker Unified Studio area utilizing the Amazon Redshift Question Editor. Entry to the editor permits Amazon Q chat integration towards your Amazon Redshift information sources.
Allow Amazon Q generative SQL
You may management entry to generative SQL on the account-Area stage within the Amazon Redshift Question Editor or on the SageMaker Unified Studio area stage. To allow this characteristic, an account admin should explicitly activate Amazon Q generative SQL. By default, the characteristic just isn’t accessible to your customers. Directors which have permission for the sqlworkbench:UpdateAccountQSqlSettings AWS Identification and Entry Administration (IAM) motion can flip the Amazon Q technology SQL characteristic on or off by the admin window, as illustrated within the following sections. When turned off, this can prohibit customers from opening the Amazon Q chat pane and assist forestall interplay with generative SQL.
Allow Amazon Q in your SageMaker area
To allow Amazon Q in your SageMaker area, you possibly can navigate to the Amazon Q tab on the area settings web page and select to allow the service. For extra data, see Amazon Q in Amazon SageMaker Unified Studio.
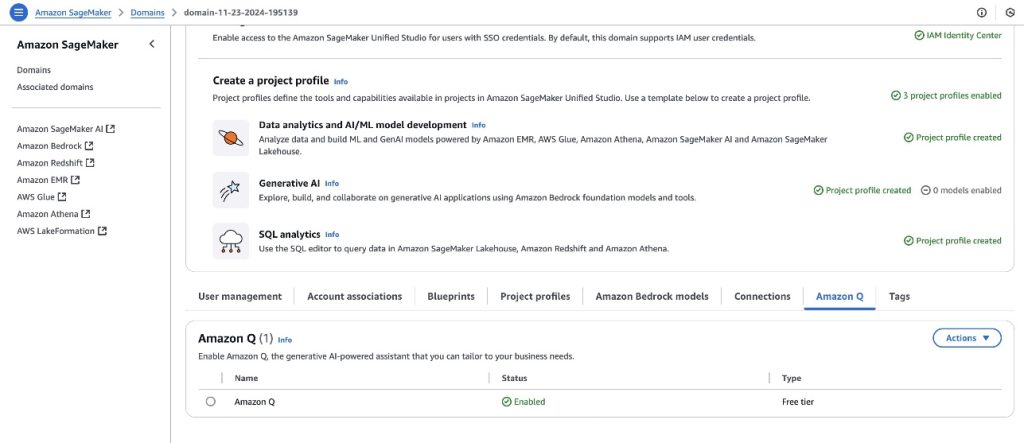
Allow Amazon Q in Amazon Redshift
To allow Amazon Q generative SQL from the Amazon Redshift Question Editor, entry the Amazon Q generative SQL settings. This requires the administrator to have the sqlworkbench:UpdateAccountQSqlSettings permission of their IAM coverage. For extra data, see Updating generative SQL settings as an administrator.
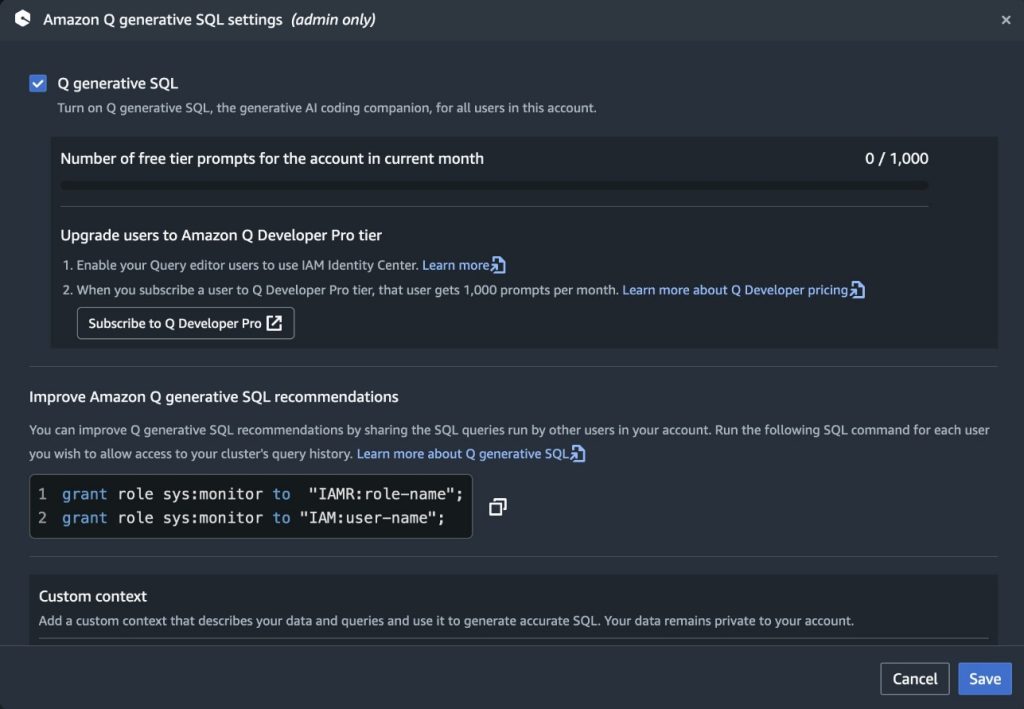
With generative SQL enabled on the account-Area stage, you possibly can prohibit entry to particular customers with IAM controls. IAM directors can construct IAM insurance policies that permit or deny entry to the motion sqlworkbench:GetQSqlRecommendations. For extra data, confer with Actions, sources, and situation keys for AWS SQL Workbench. Insurance policies can then be related to IAM customers or roles to manage entry to SQL technology at a extra granular stage. An appropriately scoped service management coverage (SCP) can be utilized to restrict entry to SQL technology to particular accounts inside your group if required.
The next is an instance coverage denying entry to make use of SQL technology:
{
“Model”: “2012-10-17”,
“Assertion”: (
{
“Sid”: “DenyAccessToAmazonQGenerativeSql”,
“Impact”: “Deny”,
“Motion”: (
“sqlworkbench:GetQSqlRecommendations”
),
“Useful resource”: “*”,
}
)
}
Cross-Area inference
Amazon Q Developer makes use of cross-Area inference to distribute site visitors throughout completely different AWS Areas, which supplies elevated throughput and resilience throughout excessive demand intervals, improved efficiency, and entry to the newest Amazon Q Developer capabilities.
When a request is made out of an Amazon Q Developer profile, it’s stored throughout the Areas in the identical geography as the unique information. Though this doesn’t change the place the info is saved, the requests and output outcomes would possibly transfer throughout Areas through the inference course of. Information is encrypted when transmitted throughout Amazon’s community. For extra data on cross-Area inference, see Cross-region processing in Amazon Q Developer.
Monitoring
To watch which IAM customers or roles are interacting with generative SQL, you should utilize AWS CloudTrail. CloudTrail screens API calls and logs which identities have carried out explicit actions. When a person first asks a query, a CloudTrail occasion is emitted referred to as IngestQSqlMetadata. This can be a results of Amazon Q beginning the metadata ingest course of. Ingestion is an asynchronous operation, so there may be a collection of GetQSqlMetadataStatus occasions. That is as a result of workflow checking the ingestion course of standing.
After the workflow has accomplished efficiently, every query sees a GetQSqlRecommendation occasion. That is the results of customers submitting questions and triggering technology of SQL statements. The next is an instance CloudTrail occasion for GetQSqlRecommendation. On this instance, Amazon Q emits detailed CloudTrail occasions highlighting the warehouse being queried, IAM principal calling Amazon Q, and your complete response construction from Amazon Q in responseElements:
{
“eventVersion”: “1.09”,
“userIdentity”: {
“sort”: “AssumedRole”,
“principalId”: “AROA123456789EXAMPLE:demouser”,
“arn”: “arn:aws:sts::111122223333:assumed-role/DemoUser”,
“accountId”: “111122223333”,
“accessKeyId”: “ASIAIOSFODNN7EXAMPLE”,
“sessionContext”: {
“sessionIssuer”: {
“sort”: “Function”,
“principalId”: “AROA123456789EXAMPLE”,
“arn”: “arn:aws:iam::111122223333:function/DemoUser”,
“accountId”: “111122223333”,
“userName”: “DemoUser”
},
“attributes”: {
“creationDate”: “2025-01-17T05:31:01Z”,
“mfaAuthenticated”: “false”
}
}
},
“eventTime”: “2025-01-17T05:34:51Z”,
“eventSource”: “sqlworkbench.amazonaws.com”,
“eventName”: “GetQSqlRecommendation”,
“awsRegion”: “us-east-1”,
“sourceIPAddress”: “122.171.17.139”,
“userAgent”: “Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:133.0) Gecko/20100101 Firefox/133.0”,
“requestParameters”: {
“dbConfig”: {
“database”: “sample_data_dev”
},
“databaseConfiguration”: {
“redshiftConfig”: {
“clusterIdentifier”: “redshift-cluster-1”,
“database”: “sample_data_dev”
}
},
“immediate”: “HIDDEN_DUE_TO_SECURITY_REASONS”,
“clientToken”: “HIDDEN_DUE_TO_SECURITY_REASONS”,
“logConfig”: {},
“sqlworkbenchConnectionArn”: “arn:aws:sqlworkbench:us-east-1:111122223333:connection/47ahg61-ce0b-4646-831b-a140ea4055ae”
},
“responseElements”: {
“information”: {
“extractionErrors”: false,
“guardRails”: {
“isDml”: false
},
“sqlStatement”: “HIDDEN_DUE_TO_SECURITY_REASONS”,
“syntaxErrors”: “HIDDEN_DUE_TO_SECURITY_REASONS”
},
“logSessionId”: “623318ad-dbcc-4f69-ae08-f85d1b63a70f”,
“questionId”: “623318ad-dbcc-4f69-ae08-f85d1b63a70f”,
“originalQuestionId”: “623318ad-dbcc-4f69-ae08-ae08asd1a”
},
“requestID”: “623318ad-dbcc-4f69-ae08-f85d1b63a70f”,
“eventID”: “ac2c1932-49b1-41b3-a1af-20fa4461cf7d”,
“readOnly”: false,
“eventType”: “AwsApiCall”,
“managementEvent”: true,
“recipientAccountId”: “111122223333”,
“eventCategory”: “Administration”,
“tlsDetails”: {
“tlsVersion”: “TLSv1.3”,
“cipherSuite”: “TLS_AES_128_GCM_SHA256”,
“clientProvidedHostHeader”: “qsql.sqlworkbench.us-east-1.amazonaws.com”
},
“sessionCredentialFromConsole”: “true”
}
Conclusion
On this submit, we mentioned the Amazon Q generative SQL workflow. We highlighted the method round utilizing your schema context alongside metadata akin to historic SQL queries and customized context. Utilizing this metadata permits the technology of related SQL that helps speed up your analyst’s productiveness. Though it’s necessary to help analysts, it’s additionally crucial to verify information stays safe and guarded. To help this, generative SQL makes use of solely the info the related person has entry to. This helps forestall publicity to data past their authorization.Once you’re seeking to enhance the relevance of generated SQL by sharing extra question historical past, it’s necessary to think about the trade-off of exposing extra data to the person. Deciding your method right here ought to take note of the area context of the info and the attainable publicity of metadata the person doesn’t have entry to, or doubtlessly delicate data which may seem in question strings. Protecting these concerns in thoughts will help you obtain the suitable safety posture to your workloads.
To get began with Amazon Q generative SQL, see Write queries quicker with Amazon Q generative SQL for Amazon Redshift and Interacting with Amazon Q generative SQL.
In regards to the authors
 Gregory Knowles is an information and AI specialist resolution architect at AWS, specializing in the UK public sector. With in depth expertise in cloud-based architectures, Greg guides public sector clients in implementing trendy information options. His experience spans governance, analytics, and AI/ML. Greg’s ardour lies in accelerating transformation and innovation to enhance productiveness and outcomes. He has efficiently led tasks that moved information methods into the cloud, adopted new information architectures, and carried out AI at scale in manufacturing.
Gregory Knowles is an information and AI specialist resolution architect at AWS, specializing in the UK public sector. With in depth expertise in cloud-based architectures, Greg guides public sector clients in implementing trendy information options. His experience spans governance, analytics, and AI/ML. Greg’s ardour lies in accelerating transformation and innovation to enhance productiveness and outcomes. He has efficiently led tasks that moved information methods into the cloud, adopted new information architectures, and carried out AI at scale in manufacturing.
 Abhinav Tripathy is a Software program Engineer and Safety Guardian at AWS, the place he develops Amazon Q generative SQL by combining machine studying, databases, and internet methods. Abhinav is enthusiastic about constructing scalable internet methods from scratch that remedy actual buyer challenges. Exterior of labor, he enjoys touring, watching soccer, and taking part in badminton.
Abhinav Tripathy is a Software program Engineer and Safety Guardian at AWS, the place he develops Amazon Q generative SQL by combining machine studying, databases, and internet methods. Abhinav is enthusiastic about constructing scalable internet methods from scratch that remedy actual buyer challenges. Exterior of labor, he enjoys touring, watching soccer, and taking part in badminton.
 Erol Murtezaoglu is a Technical Product Supervisor at AWS, is an inquisitive and enthusiastic thinker with a drive for self-improvement and studying. He has a powerful and confirmed technical background in software program improvement and structure, balanced with a drive to ship commercially profitable merchandise. Erol extremely values the method of understanding buyer wants and issues, so as to ship options that exceed expectations.
Erol Murtezaoglu is a Technical Product Supervisor at AWS, is an inquisitive and enthusiastic thinker with a drive for self-improvement and studying. He has a powerful and confirmed technical background in software program improvement and structure, balanced with a drive to ship commercially profitable merchandise. Erol extremely values the method of understanding buyer wants and issues, so as to ship options that exceed expectations.

{kind=link}
I love how you write—it’s like having a conversation with a good friend. Can’t wait to read more!This post pulled me in from the very first sentence. You have such a unique voice!Seriously, every time I think I’ll just skim through, I end up reading every word. Keep it up!Your posts always leave me thinking… and wanting more. This one was no exception!Such a smooth and engaging read—your writing flows effortlessly. Big fan here!Every time I read your work, I feel like I’m right there with you. Beautifully written!You have a real talent for storytelling. I couldn’t stop reading once I started.The way you express your thoughts is so natural and compelling. I’ll definitely be back for more!Wow—your writing is so vivid and alive. It’s hard not to get hooked!You really know how to connect with your readers. Your words resonate long after I finish reading.
your blog is fantastic! I’m learning so much from the way you share your thoughts.