



What’s a Information Graph?
To grasp why one might use a Information Graph (KG) as a substitute of one other structured knowledge illustration, it’s essential to acknowledge its give attention to express relationships between entities—resembling companies, folks, equipment, or prospects—and their related attributes or options. Not like embeddings or vector search, which prioritize similarity in high-dimensional areas, a Information Graph excels at representing the semantic connections and context between knowledge factors. A primary unit of a information graph is a reality. Information could be represented as a triplet in both of the next methods:
Two easy KG examples are proven under. The left instance of a reality may very well be . You possibly can see the KG is nothing however a group of a number of such info. However as you might discover graphs have semantics because the left instance DOES NOT describe a romantic relationship between two folks, whereas the precise instance DOES describe a romantic relationship between two folks.
Semantic relationships in Graph
Now that you simply perceive the importance of semantics in Information Graphs, let’s introduce you to the dataset we’ll use within the upcoming code examples: the BloodHound dataset. BloodHound is a specialised dataset designed for analyzing relationships and interactions inside Energetic Listing environments. It’s broadly used for safety auditing, assault path evaluation, and gaining insights into potential vulnerabilities in community buildings.
Nodes within the BloodHound dataset signify entities inside an Energetic Listing surroundings. These usually embrace:
Customers: represents particular person consumer accounts within the area.
Teams: represents safety or distribution teams that combination customers or different teams for permission assignments.
Computer systems: represents particular person machines within the community (workstations or servers).
Domains: represents the Energetic Listing area that organizes and manages customers, computer systems, and teams.
Organizational Items (OUs): represents containers used for structuring and managing objects like customers or teams.
GPOs (Group Coverage Objects): represents insurance policies utilized to customers and computer systems inside the area.
An in depth description of node entities is accessible right here. Relationships within the graph outline interactions, memberships, and permissions between nodes; a full description of the perimeters is accessible right here.
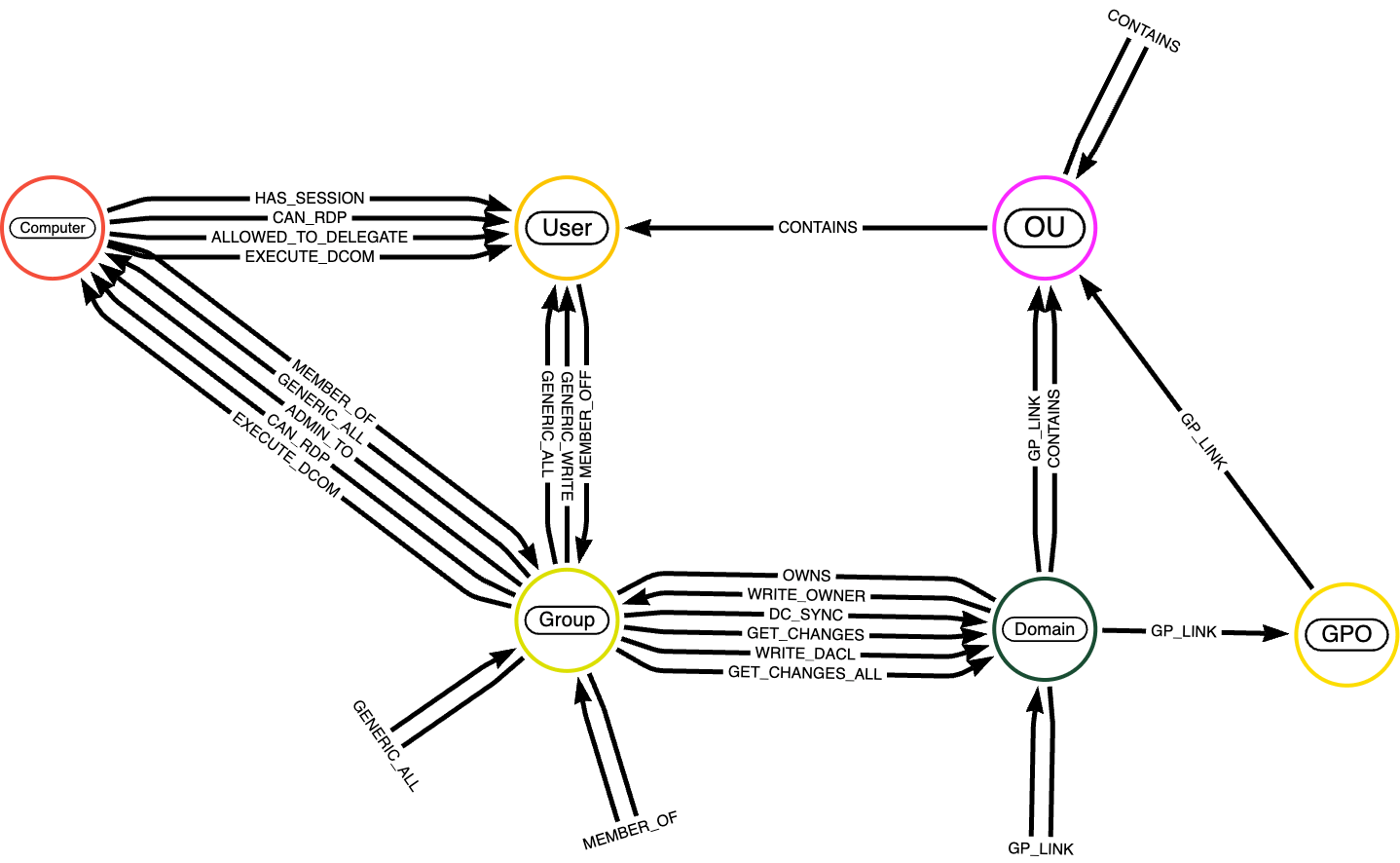
The graph mannequin of the BloodHound dataset
When to decide on GraphRAG over Conventional RAG
The first benefit of GraphRAG over commonplace RAG lies in its skill to carry out precise matching through the retrieval step. That is made doable partly by explicitly preserving the semantics of pure language queries in downstream graph question language. Whereas dense retrieval strategies based mostly on cosine similarity excel at capturing fuzzy semantics and retrieving associated data even when the question is not an actual match, there are instances the place precision is essential. This makes GraphRAG notably beneficial in domains the place ambiguity is unacceptable, resembling compliance, authorized, or extremely curated datasets.
That mentioned, the 2 approaches usually are not mutually unique and are sometimes mixed to leverage their respective strengths. Dense retrieval can solid a large web for semantic relevance, whereas the information graph refines the outcomes with precise matches or reasoning over relationships.
When to decide on Conventional RAG over GraphRAG
Whereas GraphRAG has distinctive benefits, it additionally comes with challenges. A key hurdle is defining the issue appropriately—not all knowledge or use instances are well-suited for a Information Graph. If the duty entails extremely unstructured textual content or doesn’t require express relationships, the added complexity will not be price it, resulting in inefficiencies and suboptimal outcomes.
One other problem is structuring and sustaining the Information Graph. Designing an efficient schema requires cautious planning to steadiness element and complexity. Poor schema design can affect efficiency and scalability, whereas ongoing upkeep calls for sources and experience.
Actual-time efficiency is one other limitation. Graph databases like Neo4j can wrestle with real-time queries on giant or incessantly up to date datasets resulting from advanced traversals and multi-hop queries, making them slower than dense retrieval techniques. In such instances, a hybrid method—utilizing dense retrieval for pace and graph refinement for post-query evaluation—can present a extra sensible answer.
GraphDB and embeddings
Graph DBs like Neo4j typically additionally present vector search capabilities through HNSW indexes. The distinction right here is how they use this index as a way to present higher outcomes in comparison with vector databases. While you carry out a question, Neo4j makes use of the HNSW index to determine the closest matching embeddings based mostly on measures like cosine similarity or Euclidean distance. This step is essential for locating a place to begin in your knowledge that aligns semantically with the question, leveraging the implicit semantics given by the vector search.
What units graph databases aside is their skill to mix this preliminary vector-based retrieval with their highly effective traversal capabilities. After discovering the entry level utilizing the HNSW index, Neo4j leverages the express semantics outlined by the relationships within the information graph. These relationships permit the database to traverse the graph and collect extra context, uncovering significant connections between nodes. This mix of implicit semantics from embeddings and express semantics from graph relationships allows graph databases to offer extra exact and contextually wealthy solutions than both method might obtain alone.
Finish-to-Finish GraphRAG in Databricks
GraphRAG is a superb instance of Compound AI techniques in motion, the place a number of AI elements work collectively to make retrieval smarter and extra context-aware. On this part, we’ll take a high-level take a look at how every thing matches collectively.
GraphRAG Structure
Under is an structure diagram demonstrating how an analyst’s pure language questions can retrieve data from a Neo4j information graph.
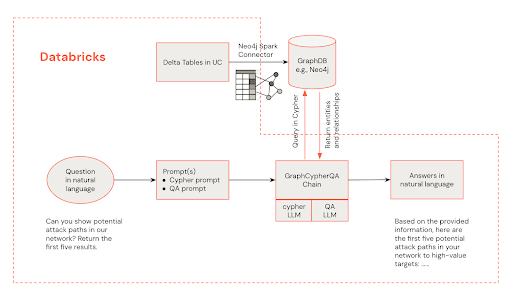
GraphRAG Structure on Databricks
The structure for GraphRAG-powered menace detection combines the strengths of Databricks and Neo4j:
Safety Operations Heart (SOC) Analyst Interface: Analysts work together with the system by Databricks, initiating queries and receiving alert suggestions.
Databricks Processing: Databricks handles knowledge processing, LLM integration, and serves because the central hub for the answer.
Neo4j Information Graph: Neo4j shops and manages the cybersecurity information graph, enabling advanced relationship queries.
Implementation Overview
For this weblog, we’re skipping the code particulars—try the GitHub repository for the total implementation. Let’s stroll by the important thing steps to construct and deploy a GraphRAG agent.
Construct a Information Graph from Delta Tables: Within the pocket book, we mentioned eventualities about structured knowledge and unstructured knowledge. The Neo4j Spark Connector gives a quite simple means of reworking knowledge in Unity Catalog into graph entities (nodes/relationships).
Deploy LLMs for Cypher Question and QA: GraphRAG requires LLMs for question technology and summarization. We demonstrated learn how to deploy gpt-4o, llama-3.x, a fine-tuned text2cypher mannequin from HuggingFace and serve them utilizing a provisioned throughput endpoint.
Create and Take a look at GraphRAG Chain: We demonstrated learn how to use completely different LLM for Cypher and QA LLMs and prompts through GraphCypherQAChain. This permits us to additional tune with glass-box tracing outcomes utilizing MLflow Tracing.
Deploy the Agent with Mosaic AI Agent Framework: Use Mosaic AI Agent Framework and MLflow to deploy the agent. Within the pocket book, the method contains logging the mannequin, registering it in Unity Catalog, deploying it to a serving endpoint, and launching a evaluation app for chatting.

A Chatbot instance through Evaluation App
Conclusion
GraphRAG is a robust but extremely customizable method to constructing brokers that ship extra deterministic, contextually related AI outputs. Nevertheless, its design is case-specific, requiring considerate structure and problem-specific tuning. By integrating information graphs with Databricks’ scalable infrastructure and instruments, you may construct end-to-end Compound AI techniques that seamlessly mix structured and unstructured knowledge to generate actionable insights with deeper contextual understanding.

{kind=link}