



Each lakehouse ought to be ‘stream-fed’
The ‘open lakehouse’ idea pioneered by Databricks years in the past has been extra broadly realized via the latest rise of Apache Iceberg™, pushed by main distributors’ investments in framework integration, tooling, catalog help, and in knowledge interoperability, committing to Iceberg as a typical substrate for an open lakehouse. Advances like the power to show Delta Lake tables to the rising Iceberg ecosystem via UniForm, Unity Catalog’s help for superior options like predictive optimization and Iceberg REST with Managed Iceberg tables, and the latest unification of the Delta/Iceberg knowledge layer in Iceberg V3 all imply that organizations can now undertake an ‘Iceberg-forward’ knowledge technique with confidence, and with out compromising their use of the wealthy function units of mature lakehouses merchandise like Databricks.
One of many key lacking gamers on this story of ubiquitous entry to cloud-resident knowledge via the lingua franca of Iceberg has been streams, specifically Kafka matters. At this time, any structured knowledge at relaxation could be simply landed natively or ‘adorned’ as Iceberg. Against this, high-value knowledge in movement flowing via a streaming platform that powers real-time apps nonetheless must be ‘ETLed’ into the goal lakehouse via a point-to-point, per-stream knowledge integration job, or by working a expensive connector infrastructure by itself cluster. Each approaches make the most of a heavyweight Kafka Shopper, placing stress in your real-time knowledge supply pipelines, and create a intermediary infrastructure element to scale, handle and observe with specialised Kafka expertise. Each approaches quantity to inserting a really expensive toll each between your real-time and analytics knowledge estates, one that actually doesn’t must exist.
As the usage of cloud object shops for backing streams has matured (Redpanda led that cost a number of years in the past) and as open desk codecs have taken middle stage in lakehouses, this marriage of stream-to-table is each handy and “meant to be”. Databricks and Redpanda ship two world-class knowledge platforms that make this strategy shine brightly and switch heads. Collectively, they create a knowledge substrate spanning real-time decisioning, analytics and AI that’s laborious to beat. Virtually, this strategy merges streams with tables with the convenience of a configuration flag. It acts like a multi-chambered dam, routing selectable streams right into a unified knowledge lake on demand, delivering up-to-the-minute insights and unlocking the identical arbitrary inclusion of information inside new analytics pipelines that the lakehouse structure gave us for tables, and now via the widened aperture that the Iceberg ecosystem offers.
Seamlessly fusing real-time and analytics knowledge infrastructure to make a ‘stream-fed lakehouse’ a push-button affair not solely unlocks huge worth, but additionally solves a tough engineering downside that calls for a considerate strategy to correctly deal with within the common case. As we hope as an instance beneath, we didn’t lower corners to hurry this functionality to market. Working with dozens of design companions (and Databricks) for over a yr, we prolonged Redpanda’s single codebase in a approach that preserves our prospects’ most well-liked deployment choices (together with BYOC on a number of clouds), maintains full Kafka compatibility (go away no workloads behind), and avoids duplication of artifacts and steps for customers wherever potential. We hope this completeness of imaginative and prescient comes via as we lay out the guiding rules for constructing Redpanda Iceberg Subjects, which at the moment are obtainable with Databricks Unity Catalog on AWS and GCP!
Run your stream-to-lakehouse platform anyplace
Our first precept was to take care of alternative and meet customers the place they’re. Redpanda already has mature multi-cloud SaaS, BYOC and self-managed choices, personal sovereign networking choices like BYOVPC, and customarily by no means forces its prospects to maneuver clouds, networks, object shops, IdPs, or the rest that might gate adoption or stop platform homeowners from positioning their streaming platform deployment (together with each knowledge and management planes), the place it makes essentially the most sense for them. No matter that alternative, customers get all options of the platform and a constant UX for each devs and admins. This single-platform product technique is what permits us to announce that Iceberg Subjects for Databricks are usually obtainable in AWS, GCP and Azure clouds immediately, and that organizations can deploy with the boldness of figuring out that if and once they do swap clouds or change to new type components, they’re deploying the identical product with the identical underlying engine, Kafka compatibility, safety mannequin, efficiency traits and administration instruments. This breadth of flexibility and consistency contrasts sharply with different choices out there.
Unity Catalog, meet essentially the most unified streaming platform
Secondly, we had been adamant about constructing this as a single system, and one that really feels prefer it. You merely can’t fuse two ideas collectively properly by bolting collectively two fully completely different software program architectures. You’ll be able to paper over some issues with a SaaS veneer, however bloated architectures leak via in pricing fashions, efficiency and TCO at a minimal, and within the worst instances into the consumer expertise. We’ve finished our greatest to keep away from that.
For builders, the ‘really feel’ of a single system means a single CRUD lifecycle and a constant UX for topics-as-tables, and for the issues they require to work (specifically, schemas). With Iceberg Subjects you by no means copy entries or conf round, nor create them twice utilizing a separate UI. You handle one entity because the supply of fact for each knowledge and schema, all the time utilizing the identical instruments. For us, which means you CRUD by way of the instruments you already use: any Kafka ecosystem device, our rpk CLI, Cloud REST APIs or any Redpanda deployment automation tooling like our K8s CRs or Terraform supplier. For schemas, it is our built-in Schema Registry with its extensively accepted customary API, which defines the Iceberg desk schema implicitly, or explicitly, as you like. All the things is configuration-driven and DevOps-friendly. And with Unity Catalog’s new Managed Iceberg tables, all of your streams are discoverable via Databricks tooling as each Iceberg and Delta Lake tables by default.
Iceberg Subjects within the Databricks Ecosystem
A single system additionally issues the platform operator, who shouldn’t want to fret about managing a number of buckets or catalogs, tuning Parquet file sizes, tables lagging streams when clusters are resource-constrained, or node failures compromising exactly-once supply. With Redpanda Iceberg Subjects, all of that is self-driving. Operators profit from dynamically batched parquet writes and transactional Iceberg commits that alter to your knowledge arrival SLAs, automated lag monitoring that generates Kafka Producer backpressure when wanted, and exactly-once supply by way of Iceberg snapshot tagging (avoiding gaps or dupes after infrastructure failures).
Redpanda manages all of your knowledge in a single bucket/container, makes use of a single Iceberg catalog in Unity Catalog (which Redpanda displays for sleek restoration), and makes tables simply discoverable by surfacing Unity Catalog’s Iceberg REST endpoint proper in Redpanda Cloud’s UI. And now, with Unity Catalog Managed Iceberg Tables, desk upkeep operations like compaction, knowledge expiry, and Predictive Optimization are built-in and run mechanically by Unity Catalog within the background, whereas Redpanda takes on the minimal upkeep operations acceptable for its function, (at present Iceberg snapshot cleanup and desk creation/deletion). Databricks admins can then safe and govern these tables utilizing all the traditional Unity Catalog privileges.
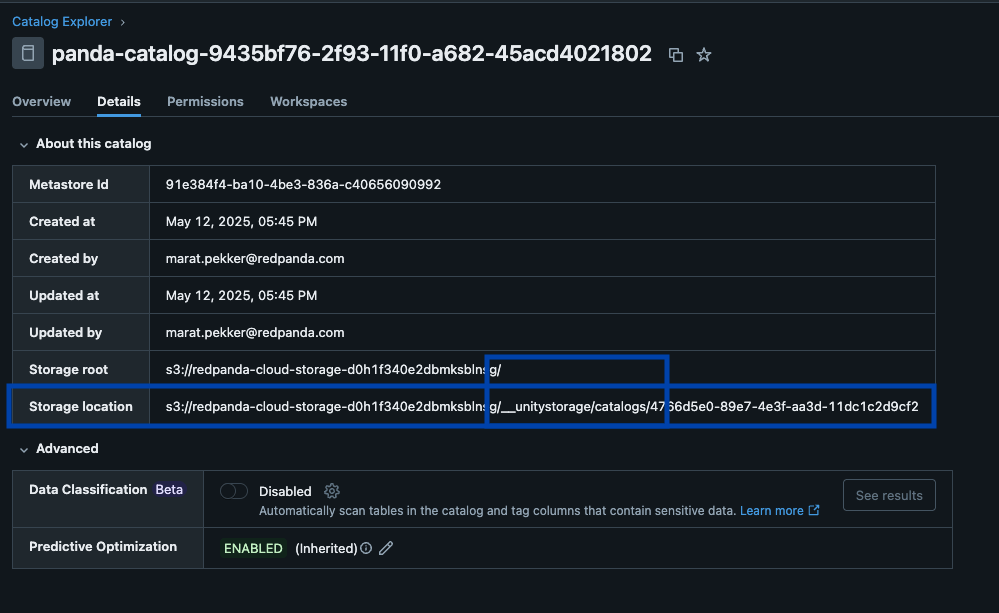
A Redpanda Iceberg catalog in Unity Catalog, with Predictive Optimization enabled
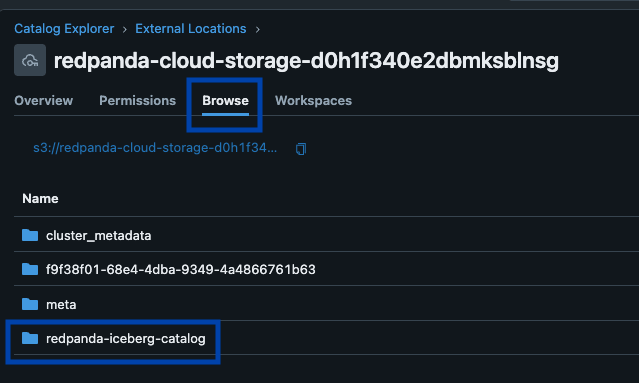
Catalog recordsdata as a part of a Unity Catalog exterior location
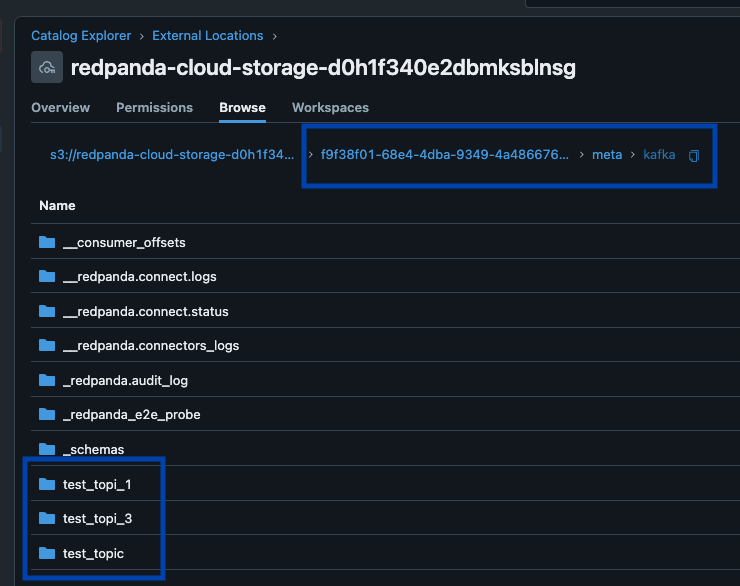
Redpanda Iceberg Subjects in a Unity Catalog exterior location
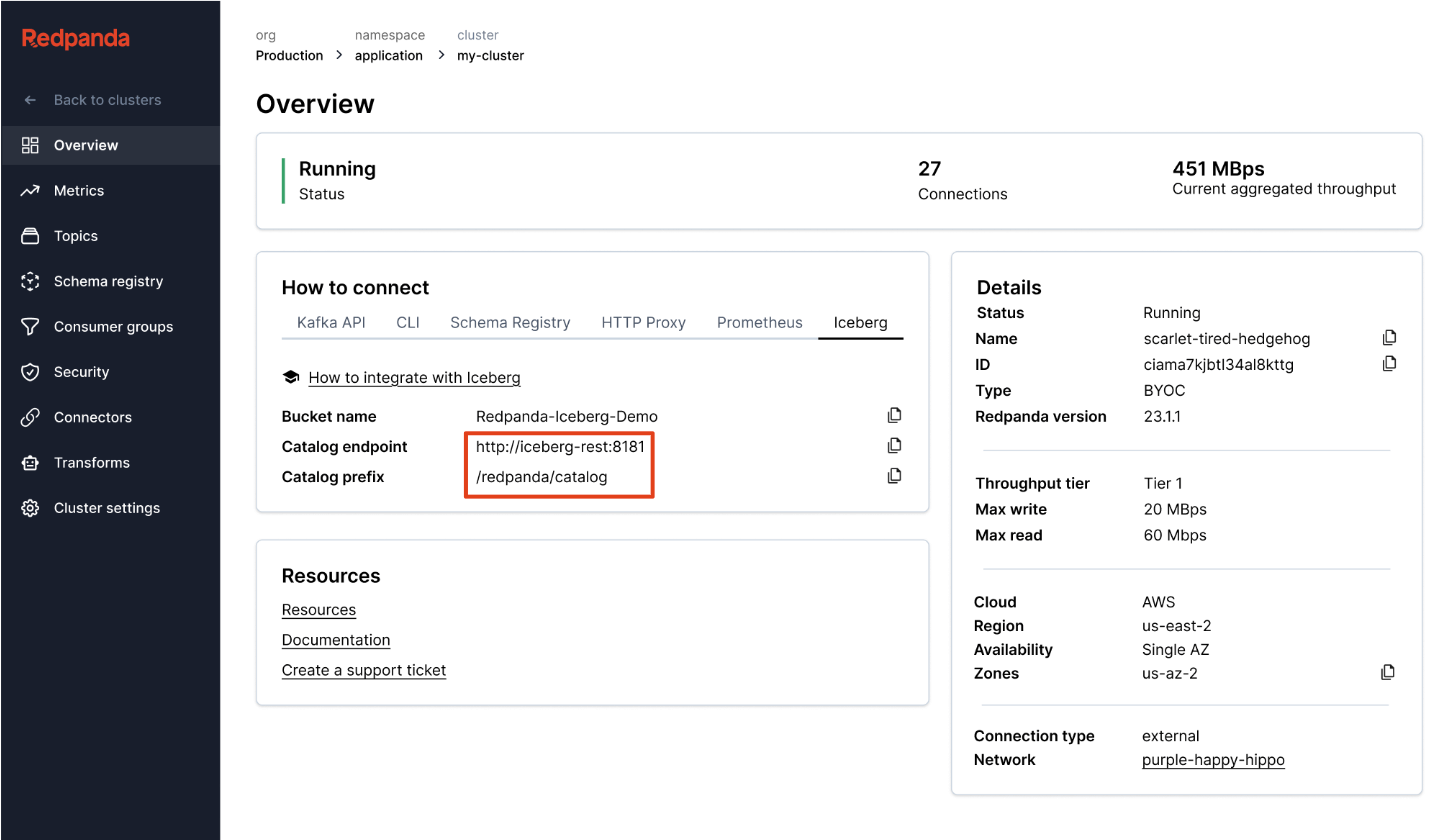
Unity Catalog’s Iceberg REST Catalog in Redpanda Cloud
One cluster to rule all of them
Most significantly, because of our R1 multi-model streaming engine that makes use of a thread-per-core structure and packs options like write caching and multi-level knowledge and workload balancing, admins can run this high-throughput Iceberg ingest in the identical cluster, and with the exact same matters that energy present low-latency Kafka workloads with sub-10ms SLAs. Utilizing asynchronous, pipelined operations locked to the identical CPU cores that deal with Produce/Devour requests, we deal with each workloads with most effectivity in a single course of. Most significantly, Iceberg Subjects can leverage the complete set of Kafka semantics, together with Kafka transactions and compacted matters, the place the Iceberg layer receives solely information from dedicated transactions. This mix of a essentially environment friendly structure that solves the laborious issues of refined semantics pays big dividends in slashing your working prices as a result of, properly, one cluster to rule all of them. No further merchandise. No separate clusters. No babysitting pipelines. Deploy anyplace. Maintain calm and keep it up, streaming platform admins.
Make it easy
Our third precept was to make some opinionated selections about default behaviors, letting customers study the system regularly with the neatest potential hands-free configuration that works for many use instances. This implies built-in hourly desk partitioning (totally divorced from Kafka matter partition schemes), always-on lifeless letter queues as tables to seize any invalid knowledge, and easy, canonical conventions like ‘newest model’ or ‘TopicNameStrategy’ for schema inference make for simple adoption. We additionally deliver Kafka metadata like message partitions, offsets, and keys alongside for the journey as an Iceberg Struct, so devs have all of the provenance to rapidly validate the correctness of their streaming pipelines in Iceberg SQL.

Default matter configuration: unified lifecycle, hourly partitioning and DLQ
The easy ought to be easy, in fact, however the refined also needs to be easy. So defining hierarchical customized partitioning with the complete set of Iceberg partition transforms or pulling a particular Protobuf message kind from inside a topic to develop into your Iceberg desk schema are, once more, simply declarative single-line matter properties. Schemas can evolve gracefully as Redpanda applies in-place desk evolution. And if you must, run a easy SMT in your favourite language that followers out advanced messages from a uncooked matter into easier Iceberg reality tables utilizing onboard Knowledge Transforms powered by WebAssembly. The final word aim is touchdown analytics-ready in a single go. Growth, whats up Bronze layer.
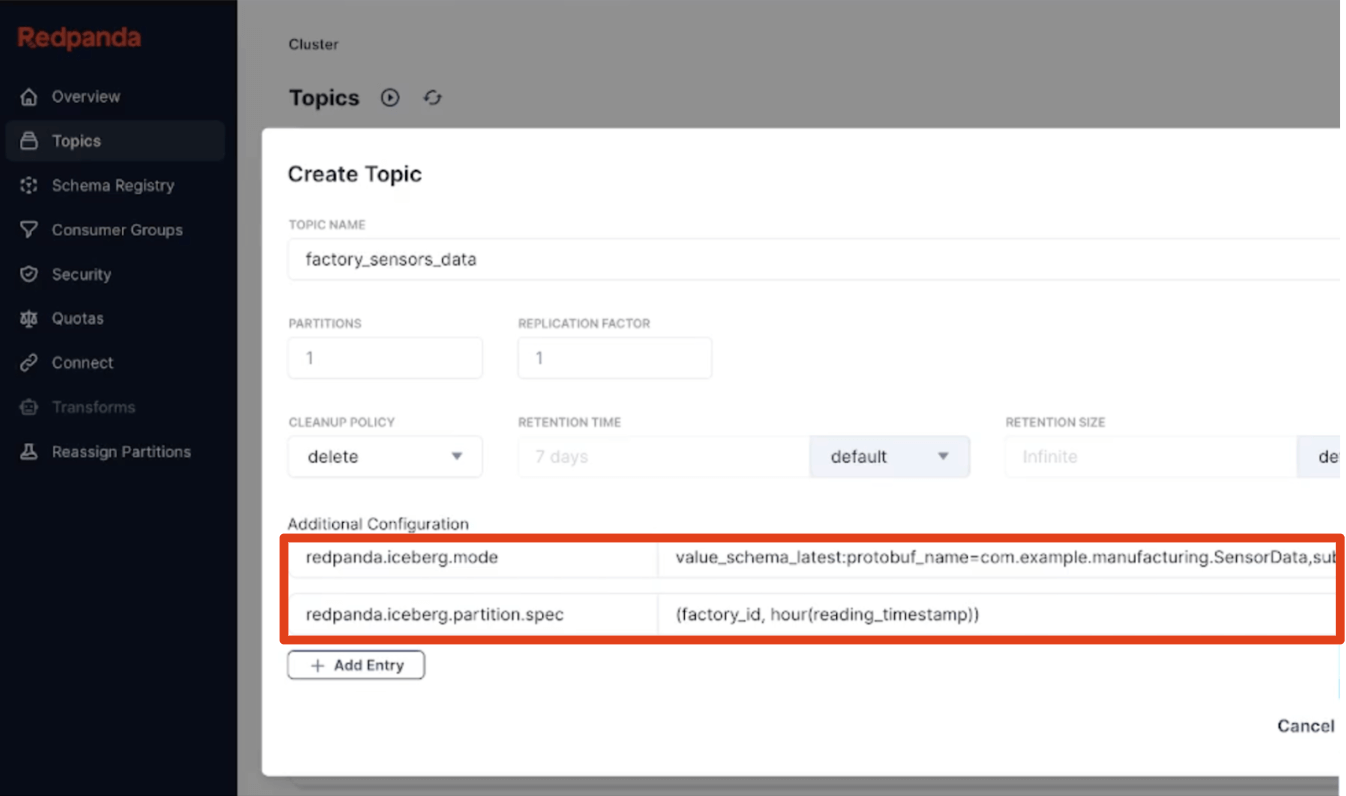
Creating an Iceberg Matter with customized partitioning and schema choice
The backdrop to all of this innovation is, in fact, the fast-evolving Apache Iceberg venture and specs, and Redpanda’s dedication extra usually to open requirements. That dedication began with its early help of the Kafka protocol, schema registry and HTTP proxy APIs, and even different particulars like customary matter configuration that enables organizations to seamlessly migrate an entire property of Kafka purposes unchanged. Within the Iceberg realm, Redpanda has stepped up as a dedicated pioneer in the neighborhood, implementing a full C++ Iceberg consumer from the bottom up (one thing not obtainable open supply). This consumer helps the complete Iceberg V2 desk spec, all schema evolution guidelines, and partition transforms. On the Iceberg catalog aspect, repanda each ships a file-based catalog and speaks Iceberg REST for operations like create, commit, replace and delete in distant catalogs like Unity Catalog, and helps OIDC authentication, dealing with your Unity Catalog credentials judiciously as a secret that is transparently encrypted in your cloud supplier’s secrets and techniques supervisor. Redpanda has additionally labored carefully with Databricks and different Iceberg leaders to discover how the spec could be prolonged to help semi-structured stream knowledge via the Variant kind, and to make managing desk RBAC extra seamless by synchronizing insurance policies throughout the 2 platforms. This standardization and all the time implementing to the spec additionally means minimal vendor lock-in. Organizations are all the time free to swap out any piece of the system in the event that they discover a higher possibility: the streaming platform, the Iceberg catalog or the lakehouse querying/processing the tables.
For those who’ve gotten this far, we sincerely hope you’ve gotten a really feel for the considerate rigor in Redpanda’s strategy to this red-hot market alternative, one which stems from a robust engineering tradition and fervour for constructing rock-solid merchandise. As technologists at coronary heart with stable monitor information, and with our concentrate on the BYOC type issue particularly, Redpanda and Databricks are completely aligned to ship two best-of-breed platforms that act and really feel like one, and one which, for you, makes the steam-to-table downside properly solved.
Strive Iceberg Subjects with Unity Catalog utilizing Redpanda’s distinctive Convey-Your-Personal-Cloud providing immediately. Or, begin with a free trial of our self-managed taste, Redpanda Enterprise!: https://cloud.redpanda.com/try-enterprise.

{kind=link}