



The subsequent era of Amazon SageMaker is the middle for all of your knowledge, analytics, and AI. Bringing collectively broadly adopted Amazon Internet Providers (AWS) machine studying (ML) and analytics capabilities, it delivers an built-in expertise for analytics and AI with unified entry to all of your knowledge. From Amazon SageMaker Unified Studio, a single knowledge and AI growth setting, you may entry your knowledge and use a collection of highly effective instruments for knowledge processing, SQL analytics, mannequin growth, coaching and inference, and generative AI growth.
With knowledge lineage, now a part of Amazon SageMaker Catalog, you may centralize lineage metadata of your knowledge property in a single place. You’ll be able to observe the circulation of knowledge over time, figuring out a transparent understanding of the place it originated, the way it has modified, and its utilization throughout the enterprise. By offering this stage of transparency, knowledge lineage helps knowledge shoppers acquire belief that the information is appropriate and compliant for his or her use instances. With knowledge lineage captured on the desk, column, and job stage, knowledge producers can conduct influence evaluation of adjustments of their knowledge pipelines and reply to knowledge points when wanted, for instance, when a column within the ensuing dataset is lacking the standard required by the enterprise.
Knowledge lineage is a strong software that may remodel how organizations perceive and handle their knowledge flows. On this put up, we discover its real-world influence by means of the lens of an ecommerce firm striving to spice up their backside line.
As an example this sensible utility, we stroll you thru how you should utilize the prebuilt integration between SageMaker Catalog and AWS Glue crawlers to robotically seize lineage for knowledge property saved in Amazon Easy Storage Service (Amazon S3) and Amazon DynamoDB. Utilizing this workflow, you may seize lineage robotically from extra knowledge sources utilizing AWS Glue crawlers. Consult with the Knowledge lineage help matrix within the SageMaker Unified Studio Consumer Information for supported sources. We additionally use SageMaker Unified Studio to navigate these knowledge property and study their origin, transformations, and dependencies, due to the lineage metadata captured utilizing the AWS Glue crawlers.
Key options of the SageMaker Catalog lineage graph
In SageMaker Unified Studio, you may discover and uncover knowledge property of your group suited in your use case. As you dive into these knowledge property, you may be taught extra about its enterprise context, schema, high quality, and lineage. Once you resolve to work with a subset of those property, you may subscribe to them in a self-service vogue and begin working with them. For extra element, go to Knowledge discovery, subscription, and consumption within the SageMaker Unified Studio Consumer Information.
SageMaker Studio gives a visible lineage graph that reveals how a knowledge asset has advanced from its supply by means of transformations to its closing state. This helps knowledge scientists, engineers, and analysts reply key questions comparable to:
The place did this knowledge come from?
What transformations has it gone by means of?
Which downstream property can be impacted by a change?
With this stage of visibility, groups can carry out quicker influence evaluation, discover the basis trigger of knowledge high quality points, and guarantee fashions are constructed on trusted knowledge. It additionally helps higher collaboration so customers can confidently use and share knowledge throughout the group. The next screenshot reveals how SageMaker Unified Studio visualizes knowledge lineage, making it simple to hint knowledge circulation and perceive dependencies.
Column-level lineage – You’ll be able to broaden column-level lineage when accessible in dataset nodes. This robotically reveals relationships with upstream or downstream dataset nodes if supply column data is on the market.
Column search – If the dataset has greater than 10 columns, the node presents pagination to navigate to columns not initially offered. To rapidly view a specific column, you may search on the dataset node that lists solely the searched column.
Particulars pane – Every lineage node captures and shows the next particulars:
Each dataset node has three tabs: LINEAGE, SCHEMA, and HISTORY. The HISTORY tab lists the completely different variations of lineage occasion captured for that node.
The job node has a particulars pane to show job particulars with the tabs Job data and Historical past. The main points pane additionally captures queries or expressions run as a part of the job.
View dataset nodes solely – If you wish to filter out the job nodes, you may select the open view management icon within the graph viewer and toggle the show dataset nodes solely, which can take away all of the job nodes from the graph and allow you to navigate solely the dataset nodes.
Model tabs – All lineage nodes in Amazon DataZone knowledge lineage could have versioning, captured as historical past, primarily based on lineage occasions captured. You’ll be able to view lineage at a specific timestamp that opens a brand new tab on the lineage web page to assist examine or distinction between the completely different timestamps.
You’ll be able to attempt a few of these options as you discover the information property of this put up. To be taught extra on knowledge lineage in SageMaker, we encourage you to dive deep into the Knowledge lineage in Amazon SageMaker Unified Studio.
Answer overview
Think about a state of affairs the place an ecommerce firm goals to optimize conversion charges and improve buyer expertise by gaining deeper insights into the shopper journey. They should join the dots between person interactions and precise purchases, however with knowledge scattered throughout a number of sources, the place do they start? That is the place knowledge lineage turns into invaluable. To carry out their evaluation, they want knowledge from two major sources:
Clickstream knowledge saved in Amazon S3 (in JSON or Parquet format)
Transactional order knowledge saved as objects in Amazon DynamoDB
To make these datasets discoverable throughout the enterprise, that you must:
Create a mission in SageMaker Unified Studio that can be used to supply and handle the datasets
Allow knowledge lineage seize within the SageMaker Unified Studio mission
Arrange the sources for this use case, which incorporates an AWS Glue knowledge supply (arrange in SageMaker Unified Studio) and AWS Glue crawler (arrange in AWS Glue)
Run the AWS Glue crawler to catalog the datasets in AWS Glue Knowledge Catalog
Supply the metadata of the information property into the SageMaker Catalog by working the information supply
Use SageMaker Unified Studio to navigate by means of the lineage of the information property and visualize their origin
Perceive how schema evolution is captured within the knowledge asset’s lineage
Conditions
To finish the steps on this put up, you want an SageMaker Unified Studio area already deployed in your AWS account. To get began rapidly in a testing setting, we recommend creating your SageMaker area utilizing the short setup choice as defined in Create an Amazon SageMaker Unified Studio area – fast setup.

Answer steps
To seize knowledge lineage for AWS Glue tables managed with AWS Glue crawlers utilizing SageMaker Unified Studio, full the steps within the following sections.
Arrange a SageMaker mission with SQL functionality
In SageMaker Unified Studio, a mission profile defines an uber template for initiatives in your Amazon SageMaker unified area. By organising a mission with the fitting tooling (mission profile), you’ll provision sources you should utilize to work with knowledge, which could embody cataloging it in SageMaker, remodeling it into new knowledge property, analyzing it to drive enterprise worth, and even use it for ML or AI functions.
To show knowledge lineage successfully, we use SageMaker SQL analytics mission profile for a streamlined setup. Though this profile affords complete knowledge analytics capabilities, we focus particularly on two key elements:
AWS Glue database – A lakehouse for storing and managing technical metadata
Knowledge supply job – Mechanically collects and tracks metadata into SageMaker Catalog
We’ve chosen this profile to bypass complicated handbook configurations so we will deal with the core ideas of knowledge lineage.
To create a brand new mission in your SageMaker area utilizing the SQL analytics mission profile, comply with the steps detailed in SQL analytics mission profile. Hold all default configurations when creating the mission.
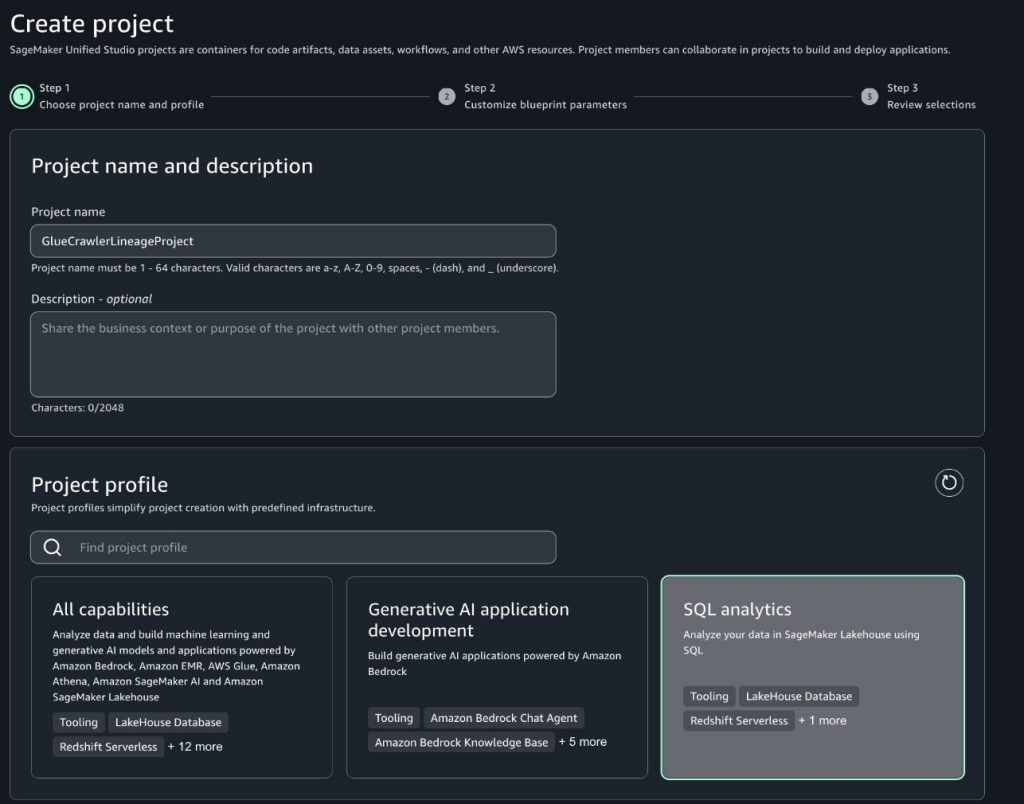
After creating your mission in SageMaker Studio, you’ll unlock highly effective knowledge lineage capabilities that make monitoring and understanding your knowledge flows intuitive. By means of the information sourcing function, you may simply monitor how knowledge strikes from supply to the AWS Glue database. This visibility turns into notably priceless when debugging knowledge points—you may rapidly hint knowledge again to its supply, perceive how adjustments influence downstream processes, and establish affected analyses or studies. Subsequent, populate the AWS Glue database with pattern knowledge to watch these options in motion and show how they’ll streamline your knowledge operations.
For additional steering on find out how to entry the small print of the brand new SageMaker mission, consult with Get mission particulars. After you entry the information supply particulars, within the Database title subject, pay attention to the AWS Glue database title related to the SageMaker mission.
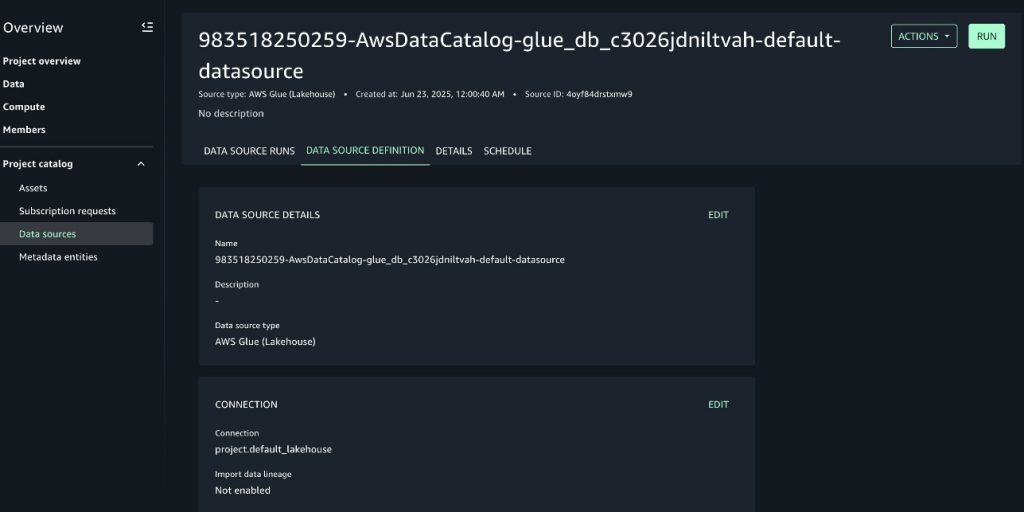
Allow knowledge lineage seize within the SageMaker mission’s knowledge supply
To allow lineage seize, comply with these steps:
Increase the Actions menu, then select Edit knowledge supply.
Go to the connections and choose Import knowledge lineage to configure lineage seize from the supply, as proven within the following screenshot.
Make different adjustments to the information supply fields as desired, then select Save.
Enabling lineage will be certain the information supply job will seize lineage within the subsequent run.
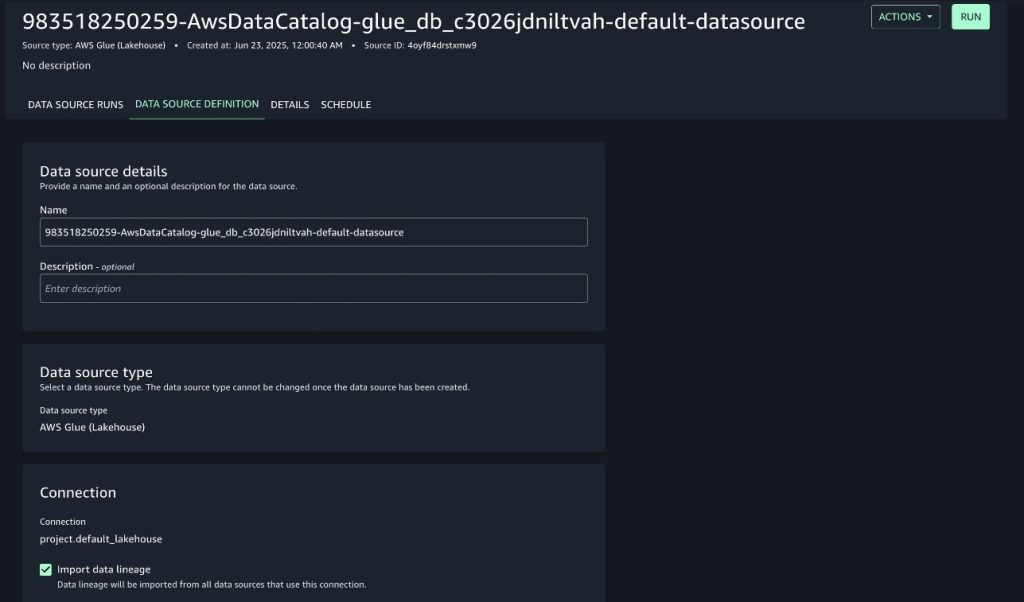
Deploy sources for the use case
Observe these steps:
To deploy the sources required for this put up, obtain the AWS CloudFormation template amazon-datazone-examples within the AWS Samples GitHub repository. Deploy it in your AWS account.
For additional steering on find out how to deploy a CloudFormation stack, consult with Create a stack from the CloudFormation console. You must present a Stack title and the title of the AWS GlueDatabaseName related to the mission of your SageMaker area, as proven within the following screenshot.
Select Subsequent.
The template will deploy the next sources:
A S3 bucket with a pattern file of clickstream knowledge. The bucket title and site of the file will comply with the trail sample s3://ecomm-analytics–/clickstream////knowledge.json. The file will include a pattern report with the next construction:
{
“session_id”: “abc123”,
“user_id”: “u789”,
“event_type”: “product_view”,
“product_id”: “prod456”,
“timestamp”: “2025-06-04T09:23:12Z”
}
A DynamoDB desk with a pattern merchandise of order knowledge (transactions). The desk can be named OrderTransactionTable. The pattern merchandise could have the next construction:
{
“order_id”: “ord789”,
“user_id”: “u789”,
“product_id”: “prod456”,
“order_total”: 79.99,
“order_timestamp”: “2025-06-04T09:27:10Z”
}
An AWS Glue crawler configured to crawl the S3 bucket and DynamoDB desk deployed as a part of the stack and retailer the metadata within the AWS Glue database related to the SageMaker mission. You’ll be able to entry the crawler’s particulars within the AWS console, as proven within the following screenshot.
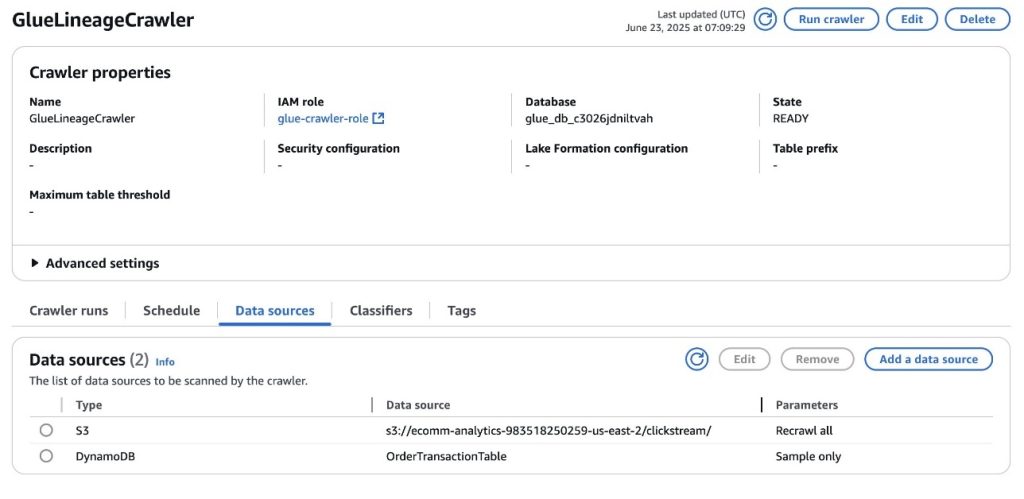
Run the AWS Glue crawler
The AWS Glue crawler deployed within the earlier step will will let you seize metadata from the 2 knowledge sources, Amazon S3 and DynamoDB, and retailer it in AWS Glue Knowledge Catalog, particularly within the database related to the SageMaker mission. After the metadata is saved, will probably be accessible to SageMaker.
Earlier than working the crawler, that you must present AWS Lake Formation permissions to the IAM function that the AWS Glue crawler will use to work together along with your knowledge supply and goal AWS Glue database. The next command will grant the permissions wanted for the crawler to retailer metadata into the AWS Glue database of the SageMaker mission.
To invoke this command, we suggest utilizing AWS CloudShell on the AWS console as defined in AWS CloudShell Ideas. Replace the , and placeholders with the fitting values in your AWS Area, AWS account ID, and title of the AWS Glue database related to the SageMaker mission.
aws lakeformation grant-permissions
–region
–principal DataLakePrincipalIdentifier=arn:aws:iam:::function/glue-crawler-role
–permissions CREATE_TABLE
–resource ‘{ “Database”: { “Title”: “” } }’
Subsequent, run the AWS Glue Crawler on the AWS console. After the crawler efficiently finishes, two new tables, clickstream and ordertransactiontable, can be created within the AWS Glue database related to the SageMaker mission. Consult with Viewing crawler outcomes and particulars to be taught extra about AWS Glue crawler outcomes.
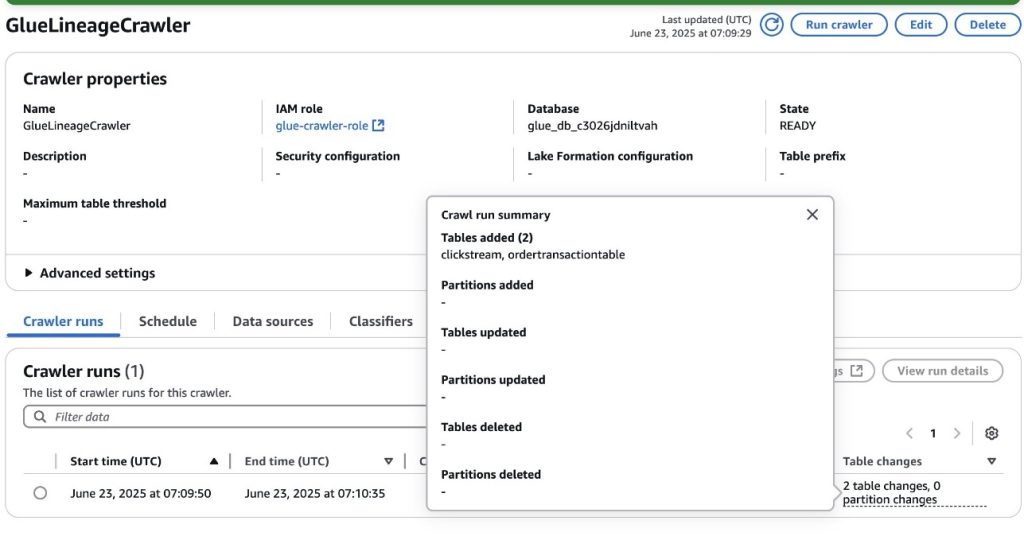
Supply metadata from the AWS Glue database into SageMaker
To supply metadata from knowledge property within the AWS Glue database, together with their lineage, into SageMaker, use the information supply that was deployed as a part of the SageMaker mission creation.
To run the information supply, go to the information supply particulars web page.
Select Run. (Knowledge sources may be scheduled to run as nicely, nonetheless, for this demonstration we set off a handbook run).
After the information supply run is full, metadata from each knowledge property within the AWS Glue database can be imported into the SageMaker area because the mission’s stock property. Yow will discover the small print of the information supply run from inside SageMaker Unified Studio, which embody:
The information property from the AWS Glue database that had been ingested into SageMaker.
The standing of the information lineage import for every knowledge asset, which incorporates an occasion ID for traceability. This lineage occasion ID can be utilized to debug inconsistencies within the ensuing lineage graph. You should use the GetLineageEvent API to retrieve the uncooked payload of the lineage occasion.
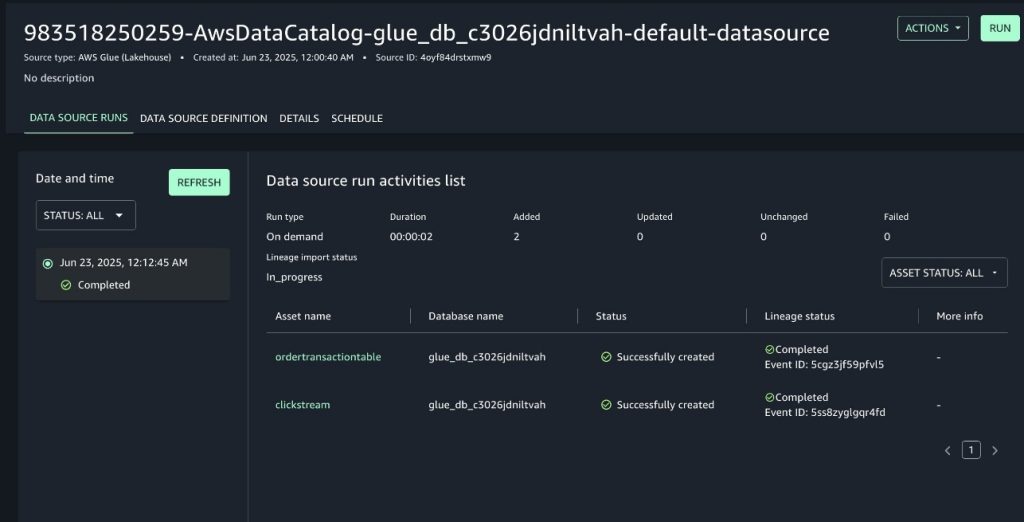
Visualizing the information lineage graph of the information property in SageMaker Unified Studio
With SageMaker Unified Studio, you might have a single place to handle and uncover knowledge property. When accessing a knowledge asset revealed within the SageMaker central catalog or in your mission’s personal stock, you may dive into the asset’s metadata, which incorporates its schema, enterprise description, customized metadata types, high quality, lineage, and extra. To visualise the lineage graph of every knowledge asset of this put up, comply with these steps:
In SageMaker Studio, navigate to the Belongings part of the SageMaker mission particulars web page and select INVENTORY
Choose the asset that you simply wish to discover. You can too entry the asset straight from the information supply run by deciding on the asset title.
To view the lineage graph of the information asset as much as its origin, proven within the following screenshots, select the LINEAGE tab.
For clickstream desk (Sourced from S3)
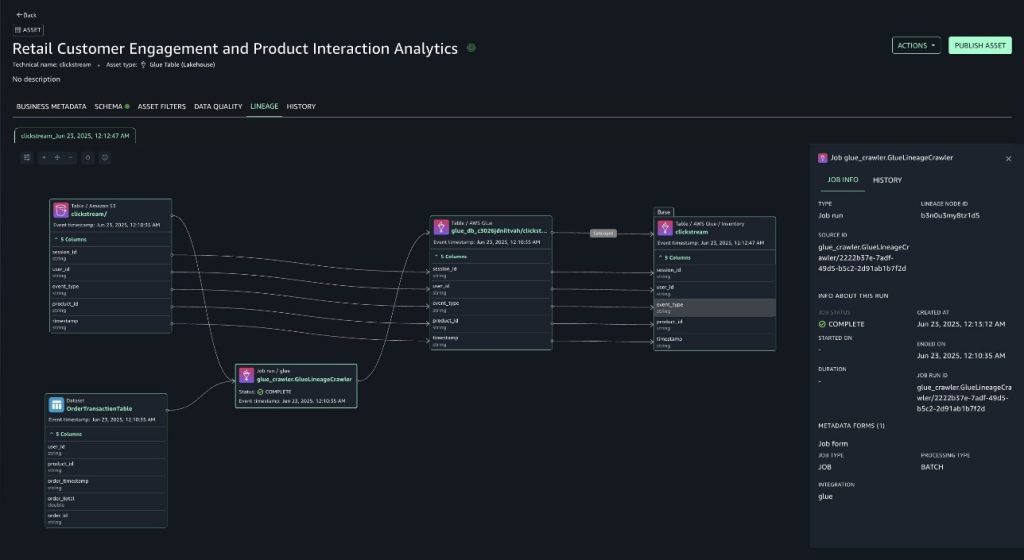
For order transactions desk (Sourced from DynamoDB)
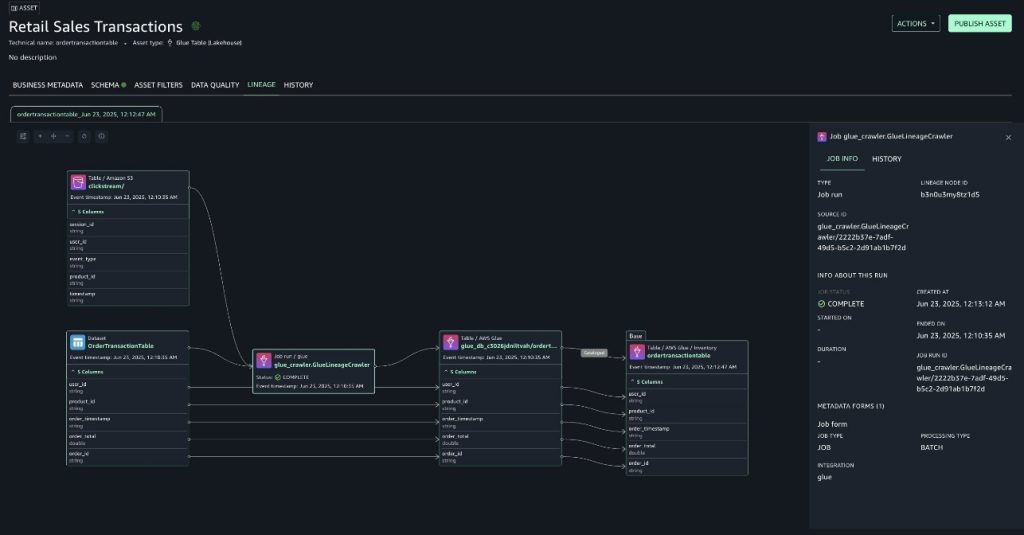
With lineage, now you can verify that the information originated from sources comparable to Amazon S3 and Amazon DynamoDB and perceive the way it has been reworked alongside the best way. Due to this end-to-end visibility, you may belief the information, make knowledgeable selections, and supply compliance with confidence. The lineage graph captures important metadata that types the muse of lineage monitoring.
This consists of desk schemas, column definitions and their knowledge varieties.
Column-level lineage turns into notably highly effective on this context. Think about your clickstream’s AWS Glue desk powers an Amazon QuickSight dashboard analyzing buyer buy patterns and see discrepancies in your income studies. With column lineage, you may immediately hint the supply of these columns.
This granular visibility not solely accelerates debugging but additionally proves invaluable throughout schema adjustments, as we present within the following part by altering the supply schema.
The crawler particulars comparable to crawlerRunId (current within the supply identifier of the lineage node) and crawler begin and finish occasions can be utilized to debug which crawler runs up to date the desk.
Understanding your knowledge asset’s schema evolution by means of lineage in SageMaker Unified Studio
Think about the order transactions supply in DynamoDB was up to date with new data. As a result of this supply powers an Amazon QuickSight report for the shopper utilizing the AWS Glue database desk, it’s necessary for shoppers to know what adjustments within the knowledge pipeline up to date the report.
Edit the DynamoDB desk merchandise with extra columns to learn the way lineage graph can be utilized to view historic updates:
{
“order_id”: “ord789”,
“user_id”: “u789”,
“product_id”: “prod456”,
“order_total”: 79.99,
“order_timestamp”: “2025-06-04T09:27:10Z”,
“customerSegment”: “new-customer”,
“conversionSource”: “primeDayEmailCampaign”
}
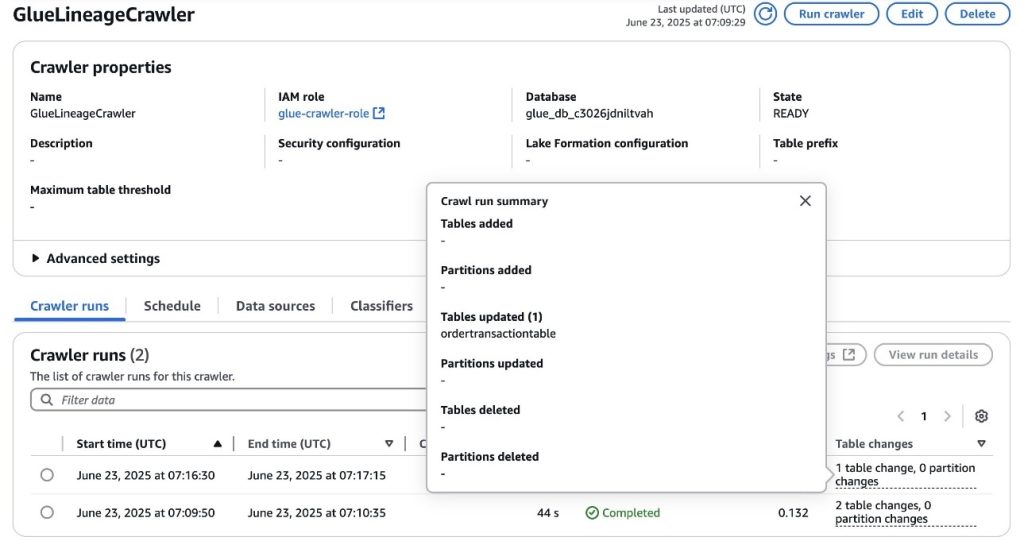
Enter the OrderTransactionsCrawler Glue crawler once more on the AWS console. After completion, you’ll discover that it up to date the ordertransactiontable AWS Glue desk, as proven within the following screenshot.
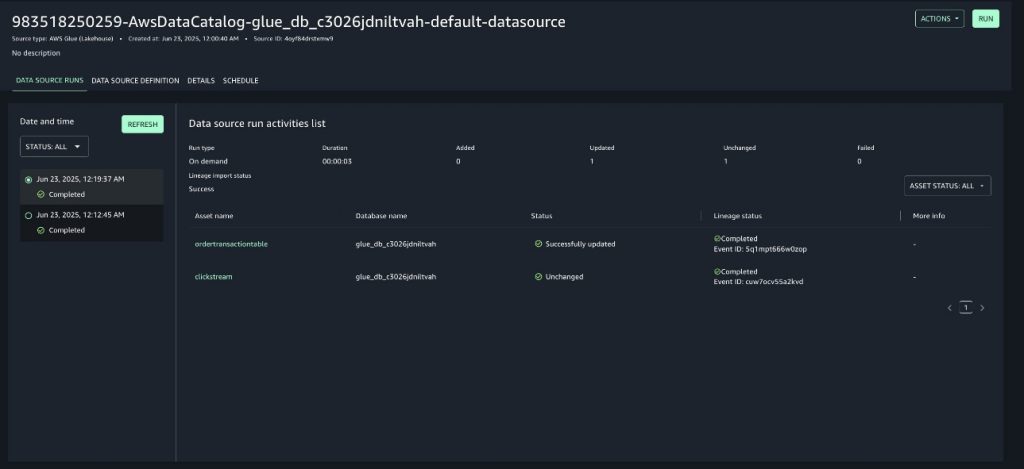
Run once more the information supply related to the mission in SageMaker Unified Studio to import the newest metadata into the SageMaker Catalog. After completion, you’ll discover the information supply up to date the ordertransactiontable knowledge asset within the SageMaker Catalog, as proven within the following screenshot.
This part explores how lineage may be helpful to trace the updates.
Navigate to the ordertransactiontable knowledge asset in SageMaker Catalog by deciding on it from the information supply run and select the LINEAGE tab, as proven within the following screenshot.
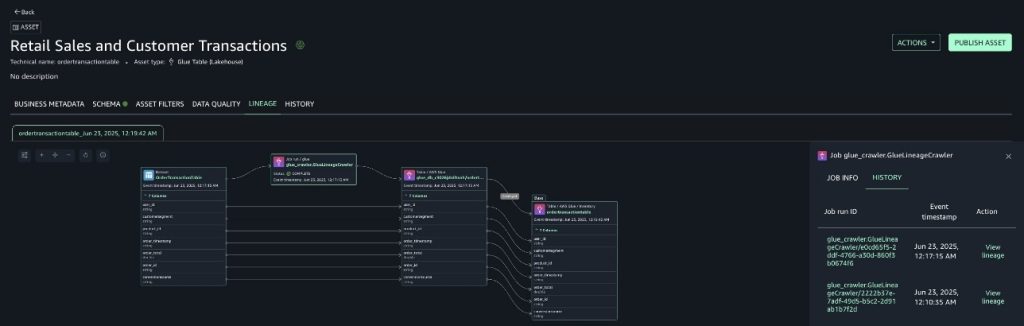
Discover how the brand new columns can be found within the lineage graph. A brand new crawler run ID is current because the supply identifier of the crawler lineage node. The historical past tab reveals a number of crawler runs. You’ll be able to navigate to examine the state of the system throughout the first run.
Cleanup
After you’re completed, we suggest to cleansing up the sources created for this put up to keep away from unintended costs:
Delete the stock property that had been cataloged within the SageMaker mission’s stock, as defined in Delete an Amazon SageMaker Unified Studio asset.
Delete the SageMaker mission that was created as a part of this put up, as defined in Delete a mission.
Delete the CloudFormation stack that was deployed as a part of this put up, as defined in Delete a stack from the CloudFormation console.
The S3 bucket created as a part of the CloudFormation stack will stay after its deletion as a result of it incorporates a knowledge file in it. Empty and delete the bucket, as defined in Deleting a common objective bucket.
Conclusion
On this put up, you had been in a position to discover the information lineage capabilities of Amazon SageMaker, particularly when working with AWS Glue crawlers. You discovered how one can arrange an AWS Glue crawler to deduce metadata from knowledge property in a number of sources comparable to Amazon S3 and DynamoDB and retailer it the AWS Glue Knowledge Catalog. You additionally imported this metadata, together with knowledge lineage, into Amazon SageMaker by means of the information supply functionality of a SageMaker mission. Lastly, you explored the ensuing lineage graph of knowledge property in SageMaker Unified Studio and noticed a number of the functionalities accessible to know the origin path of them, perceive how columns are reworked, and what influence seems like when performing adjustments to any step of the pipeline.We encourage you to now take a look at the capabilities you explored on this put up with your personal knowledge. By following the sample offered on this put up, many shoppers have been in a position to obtain governance of their knowledge lake and lakehouse platforms on prime of Amazon SageMaker with knowledge lineage and extra.
Concerning the authors
 Mohit Dawar is a Senior Software program Engineer at Amazon Internet Providers (AWS) engaged on Amazon DataZone. Over the previous 3 years, he has led efforts across the core metadata catalog, generative AI–powered metadata curation, and lineage visualization. He enjoys engaged on large-scale distributed programs, experimenting with AI to enhance person expertise, and constructing instruments that make knowledge governance really feel easy. Join with him on LinkedIn: Mohit Dawar.
Mohit Dawar is a Senior Software program Engineer at Amazon Internet Providers (AWS) engaged on Amazon DataZone. Over the previous 3 years, he has led efforts across the core metadata catalog, generative AI–powered metadata curation, and lineage visualization. He enjoys engaged on large-scale distributed programs, experimenting with AI to enhance person expertise, and constructing instruments that make knowledge governance really feel easy. Join with him on LinkedIn: Mohit Dawar.
 Jose Romero is a Senior Options Architect for Startups at Amazon Internet Providers (AWS) primarily based in Austin, TX, US. He’s enthusiastic about serving to clients architect trendy platforms at scale for knowledge, AI, and ML. As a former senior architect in AWS Skilled Providers, he enjoys constructing and sharing options for frequent complicated issues in order that clients can speed up their cloud journey and undertake finest practices. Join with him on LinkedIn: Jose Romero.
Jose Romero is a Senior Options Architect for Startups at Amazon Internet Providers (AWS) primarily based in Austin, TX, US. He’s enthusiastic about serving to clients architect trendy platforms at scale for knowledge, AI, and ML. As a former senior architect in AWS Skilled Providers, he enjoys constructing and sharing options for frequent complicated issues in order that clients can speed up their cloud journey and undertake finest practices. Join with him on LinkedIn: Jose Romero.

{kind=link}