



Apache Spark™ has change into the de facto engine for large information processing, powering workloads at among the largest organizations on the planet. Over the previous decade, we’ve seen Apache Spark evolve from a strong general-purpose compute engine right into a important layer of the Open Lakehouse Structure – with Spark SQL, Structured Streaming, open desk codecs, and unified governance serving as pillars for contemporary information platforms.
With the current launch of Apache Spark 4.0, that evolution continues with main advances in streaming, Python, SQL, and semi-structured information. You possibly can learn extra in regards to the launch right here.
Constructing upon the sturdy basis of Apache Spark, we’re excited to announce a brand new addition to open supply:
We’re donating Declarative Pipelines – a confirmed customary for constructing dependable, scalable information pipelines – to Apache Spark.
This contribution extends Apache Spark’s declarative energy from particular person queries to full pipelines – permitting customers to outline what their pipeline ought to do, and letting Apache Spark work out find out how to do it. The design attracts on years of observing real-world Apache Spark workloads, codifying what we’ve discovered right into a declarative API that covers the commonest patterns – together with each batch and streaming flows.
Pattern Dataflow Graph
Declarative APIs make ETL less complicated and extra maintainable
Via years of working with real-world Spark customers, we’ve seen frequent challenges emerge when constructing manufacturing pipelines:
An excessive amount of time spent wiring collectively pipelines with “glue code” to deal with incremental ingestion or deciding when to materialize datasets. That is undifferentiated heavy lifting that each crew finally ends up sustaining as an alternative of specializing in core enterprise logic
Reimplementing the identical patterns throughout groups, resulting in inconsistency and operational overhead
Missing a standardized framework for testing, lineage, CI/CD, and monitoring at scale
At Databricks, we started addressing these challenges by codifying frequent engineering greatest practices right into a product referred to as DLT. DLT took a declarative method: as an alternative of wiring up all of the logic your self, you specify the ultimate state of your tables, and the engine takes care of issues like dependency mapping, error dealing with, checkpointing, failures, and retries for you.
The end result was a giant leap ahead in productiveness, reliability, and maintainability – particularly for groups managing complicated manufacturing pipelines.
Since launching DLT, we’ve discovered lots.
We’ve seen the place the declarative method could make an outsized impression; and the place groups wanted extra flexibility and management. We’ve seen the worth of automating complicated logic and streaming orchestration; and the significance of constructing on open Spark APIs to make sure portability and developer freedom.
That have knowledgeable a brand new course: A primary-class, open-source, Spark-native framework for declarative pipeline growth.
From Queries to Finish-to-Finish Pipelines: The Subsequent Step in Spark’s Declarative Evolution
Apache Spark SQL made question execution declarative: as an alternative of implementing joins and aggregations with low-level RDD code, builders might merely write SQL to explain the end result they needed, and Spark dealt with the remainder.
Spark Declarative Pipelines builds on that basis and takes it a step additional – extending the declarative mannequin past particular person queries to full pipelines spanning a number of tables. Now, builders can outline what datasets ought to exist and the way they’re derived, whereas Spark determines the optimum execution plan, manages dependencies, and handles incremental processing routinely.
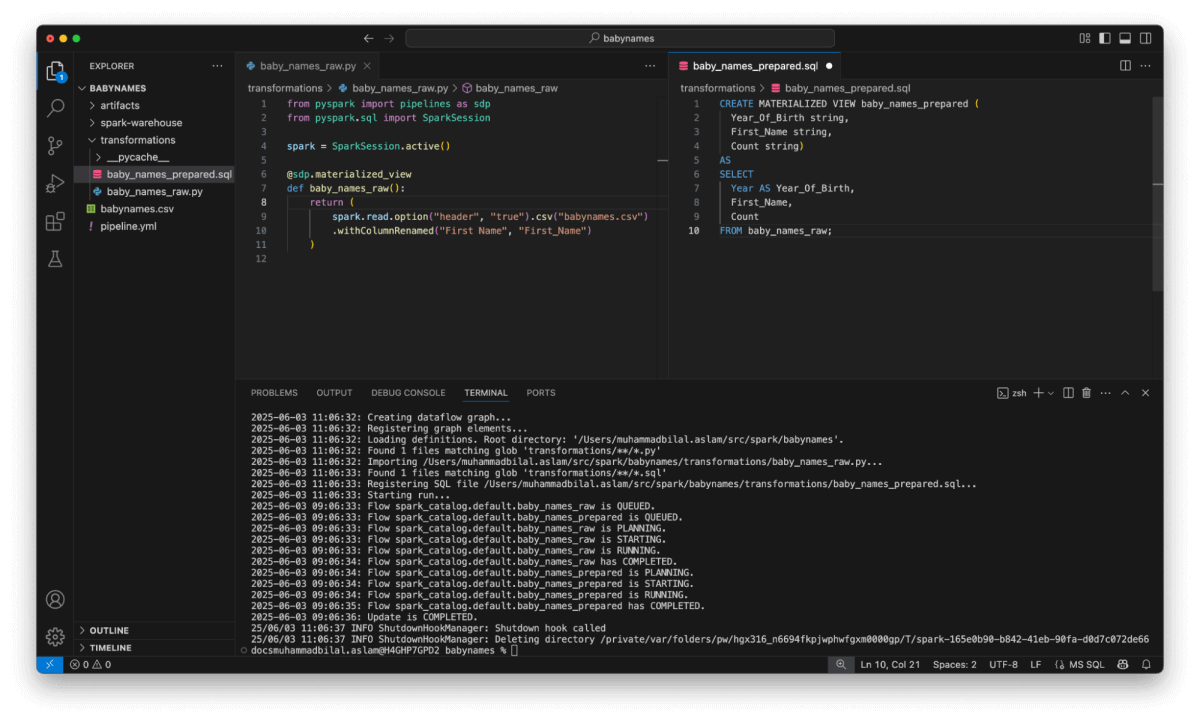
Spark Declarative Pipelines in motion
Constructed with openness and composability in thoughts, Spark Declarative Pipelines presents:
Declarative APIs for outlining tables and transformations
Native help for each batch and streaming information flows
Information-aware orchestration with computerized dependency monitoring, execution ordering, and backfill dealing with
Computerized checkpointing, retries, and incremental processing for streaming information
Help for each SQL and Python
Execution transparency with full entry to underlying Spark plans
And most significantly, it’s Apache Spark all the best way down – no wrappers or black bins.
A New Customary, Now within the Open
This contribution represents years of labor throughout Apache Spark, Delta Lake, and the broader open information neighborhood. It’s impressed by what we’ve discovered from constructing DLT – however designed to be extra versatile, extra extensible, and absolutely open supply.
And we’re simply getting began. We’re contributing this as a typical layer your complete Apache Spark ecosystem can construct upon – whether or not you’re orchestrating pipelines in your personal platform, constructing domain-specific abstractions, or contributing on to Spark itself. This framework is right here to help you.
“Declarative pipelines cover the complexity of contemporary information engineering underneath a easy, intuitive programming mannequin. As an engineering supervisor, I like the truth that my engineers can deal with what issues most to the enterprise. It’s thrilling to see this degree of innovation now being open sourced-making it accessible to much more groups.”
— Jian (Miracle) Zhou, Senior Engineering Supervisor, Navy Federal Credit score Union

“At 84.51 we’re at all times on the lookout for methods to make our information pipelines simpler to construct and preserve, particularly as we transfer towards extra open and versatile instruments. The declarative method has been a giant assist in decreasing the quantity of code we now have to handle, and it’s made it simpler to help each batch and streaming with out stitching collectively separate programs. Open-sourcing this framework as Spark Declarative Pipelines is a superb step for the Spark neighborhood.”
— Brad Turnbaugh, Sr. Information Engineer, 84.51°

What’s Subsequent
Keep tuned for extra particulars within the Apache Spark documentation. Within the meantime, you may evaluate the Exist and neighborhood dialogue for the proposal.
For those who’re constructing pipelines with Apache Spark at the moment, we invite you to discover the declarative mannequin. Our purpose is to make pipeline growth less complicated, extra dependable, and extra collaborative for everybody.
The Lakehouse is about extra than simply open storage. It’s about open codecs, open engines – and now, open patterns for constructing on prime of them.
We imagine declarative pipelines will change into a brand new customary for Apache Spark growth. And we’re excited to construct that future collectively, with the neighborhood, within the open.

{kind=link}