



We’re excited to introduce our latest on-device small language mannequin, Mu. This mannequin addresses eventualities that require inferring advanced input-output relationships and has been designed to function effectively, delivering excessive efficiency whereas working domestically. Particularly, that is the language mannequin that powers the agent in Settings, obtainable to Home windows Insiders within the Dev Channel with Copilot+ PCs, by mapping pure language enter queries to Settings operate calls.
Mu is absolutely offloaded onto the Neural Processing Unit (NPU) and responds at over 100 tokens per second, assembly the demanding UX necessities of the agent in Settings state of affairs. This weblog will present additional particulars on Mu’s design and coaching and the way it was fine-tuned to construct the agent in Settings.
Your Mannequin coaching
Enabling Phi Silica to run on NPUs offered us with invaluable insights about tuning fashions for optimum efficiency and effectivity. These knowledgeable the event of Mu, a micro-sized, task-specific language mannequin designed from the bottom as much as run effectively on NPUs and edge gadgets.
Encoder-Decoder Structure in comparison with Decoder-only Structure
Mu is an environment friendly 330M encoder–decoder language mannequin optimized for small-scale deployment, significantly on the NPUs on Copilot+ PCs. It follows a transformer encoder–decoder structure, which means an encoder first converts the enter right into a fixed-length latent illustration, and a decoder then generates output tokens primarily based on that illustration.
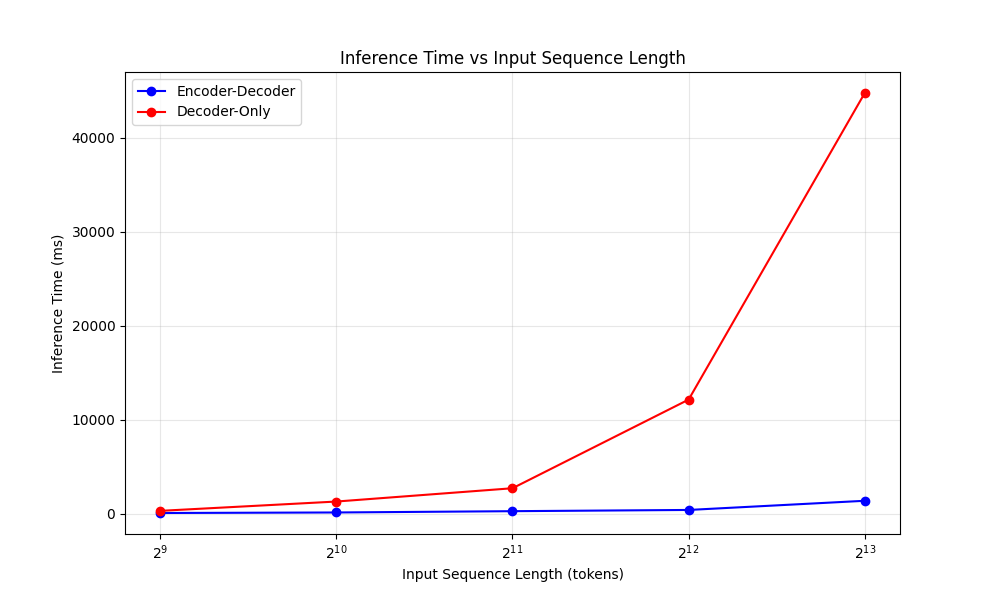
This design yields vital effectivity advantages. The determine above illustrates how an encoder-decoder reuses the enter’s latent illustration whereas a decoder-only should contemplate the total enter + output sequence. By separating the enter tokens from output tokens, Mu’s one-time encoding drastically reduces computation and reminiscence overhead. In observe, this interprets to decrease latency and better throughput on specialised {hardware}. For instance, on a Qualcomm Hexagon NPU (a cell AI accelerator), Mu’s encoder–decoder strategy achieved about 47% decrease first-token latency and 4.7× increased decoding pace in comparison with a decoder-only mannequin of comparable dimension. These good points are essential for on-device and real-time functions.
Mu’s design was fastidiously tuned for the constraints and capabilities of NPUs. This concerned adjusting mannequin structure and parameter shapes to raised match the {hardware}’s parallelism and reminiscence limits. We selected layer dimensions (corresponding to hidden sizes and feed-forward community widths) that align with the NPU’s most well-liked tensor sizes and vectorization items, making certain that matrix multiplications and different operations run at peak effectivity. We additionally optimized the parameter distribution between the encoder and decoder – empirically favoring a 2/3–1/3 break up (e.g. 32 encoder layers vs 12 decoder layers in a single configuration) to maximise efficiency per parameter.
Moreover, Mu employs weight sharing in sure parts to scale back the entire parameter rely. As an example, it ties the enter token embeddings and output embeddings, in order that one set of weights is used for each representing enter tokens and producing output logits. This not solely saves reminiscence (essential on memory-constrained NPUs) however may enhance consistency between encoding and decoding vocabularies.
Lastly, Mu restricts its operations to these NPU-optimized operators supported by the deployment runtime. By avoiding any unsupported or inefficient ops, Mu absolutely makes use of the NPU’s acceleration capabilities. These hardware-aware optimizations collectively make Mu extremely suited to quick, on-device inference.
Packing efficiency in a tenth the dimensions
Mu provides three key transformer upgrades that squeeze extra efficiency from a smaller mannequin:
Twin LayerNorm (pre- and post-LN) – normalizing each earlier than and after every sub-layer retains activations well-scaled, stabilizing coaching with minimal overhead.
Rotary Positional Embeddings (RoPE) – complex-valued rotations embed relative positions immediately in consideration, bettering long-context reasoning and permitting seamless extrapolation to sequences longer than these seen in coaching.
Grouped-Question Consideration (GQA) – sharing keys / values throughout head teams slashes consideration parameters and reminiscence whereas preserving head range, slicing latency and energy on NPUs.
Coaching strategies corresponding to warmup-stable-decay schedules and the Muon optimizer have been used to additional refine its efficiency. Collectively, these decisions ship stronger accuracy and quicker inference inside Mu’s tight edge-device funds.
We skilled Mu utilizing A100 GPUs on Azure Machine Studying, going down over a number of phases. Following the strategies pioneered first within the growth of the Phi fashions, we started with pre-training on a whole lot of billions of the highest-quality instructional tokens, to study language syntax, grammar, semantics and a few world data.
To proceed to reinforce accuracy, the subsequent step was distillation from Microsoft’s Phi fashions. By capturing among the Phi’s data, Mu fashions obtain outstanding parameter effectivity. All of this yields a base mannequin that’s well-suited to quite a lot of duties – however pairing with task-specific knowledge together with further fine-tuning via low-rank adaption (LoRA) strategies, can dramatically enhance the efficiency of the mannequin.
We evaluated Mu’s accuracy by fine-tuning on a number of duties, together with SQUAD, CodeXGlue and Home windows Settings agent (which we’ll speak extra about later on this weblog). For a lot of duties, the task-specific Mu achieves outstanding efficiency regardless of its micro-size of some hundred million parameters.
When evaluating Mu to a equally fine-tuned Phi-3.5-mini, we discovered that Mu is almost comparable in efficiency regardless of being one-tenth of the dimensions, able to dealing with tens of 1000’s of enter context lengths and over 100 output tokens per second.
Activity Mannequin
Fantastic-tuned Mu
Fantastic-tuned Phi
SQUAD
0.692
0.846
CodeXGlue
0.934
0.930
Settings Agent
0.738
0.815
Mannequin quantization and mannequin optimization
To allow the Mu mannequin to run effectively on-device, we utilized superior mannequin quantization strategies tailor-made to NPUs on Copilot+ PCs.
We used Put up-Coaching Quantization (PTQ) to transform the mannequin weights and activations from floating level to integer representations – primarily 8-bit and 16-bit. PTQ allowed us to take a totally skilled mannequin and quantize it with out requiring retraining, considerably accelerating our deployment timeline and optimizing for effectively working on Copilot+ gadgets. In the end, this strategy preserved mannequin accuracy whereas drastically lowering reminiscence footprint and compute necessities with out impacting the consumer expertise.
Quantization was only one a part of the optimization pipeline. We additionally collaborated carefully with our silicon companions at AMD, Intel and Qualcomm to make sure that the quantized operations when working Mu have been absolutely optimized for the goal NPUs. This included tuning mathematical operators, aligning with hardware-specific execution patterns and validating efficiency throughout totally different silicon. The optimization steps end in extremely environment friendly inferences on edge gadgets, producing outputs at greater than 200 tokens/second on a Floor Laptop computer 7.
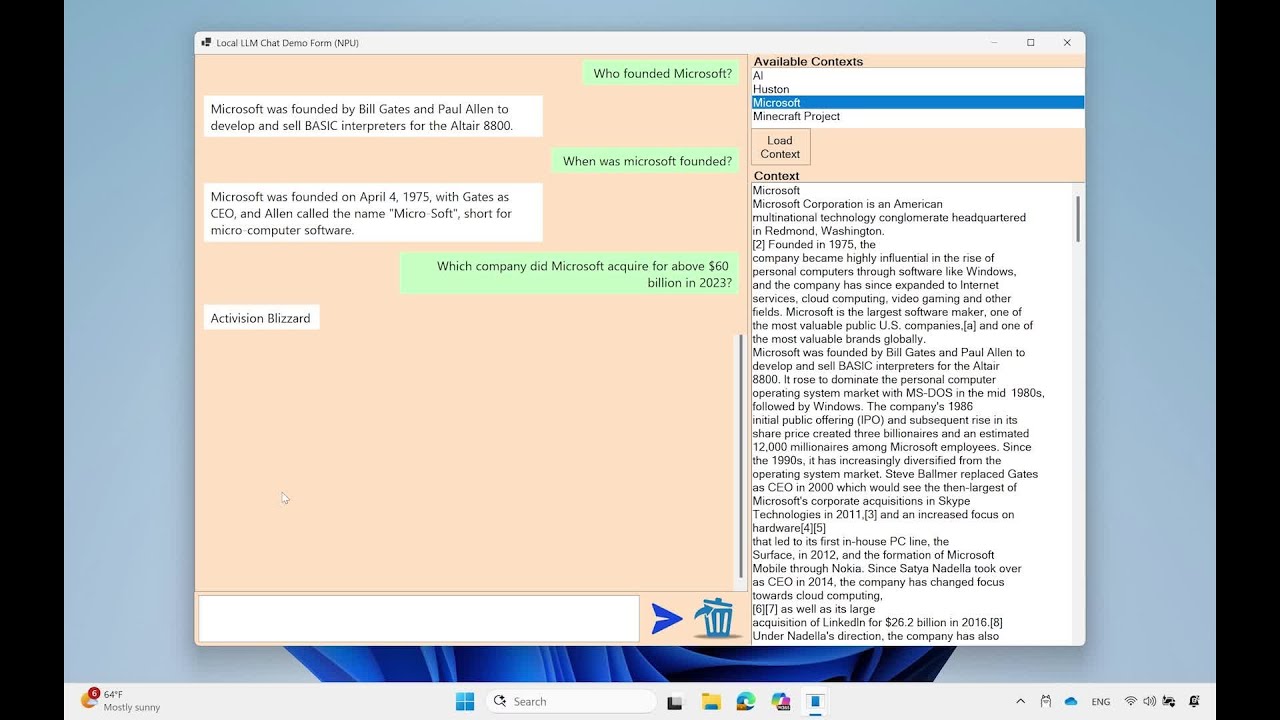
Mu working a question-answering job on an edge gadget, utilizing context sourced from Wikipedia: (https://en.wikipedia.org/wiki/Microsoft)
Discover the quick token throughputs and ultra-fast time to first token responses regardless of the big quantity of enter context offered to the mannequin.
By pairing state-of-the-art quantization strategies with hardware-specific optimizations, we ensured that Mu is extremely efficient for real-world deployments on resource-constrained functions. Within the subsequent part, we go into element on how Mu was fine-tuned and utilized to construct the brand new Home windows agent in Settings on Copilot+ PCs.
Mannequin tuning the agent in Settings
To enhance Home windows’ ease of use, we centered on addressing the problem of adjusting a whole lot of system settings. Our purpose was to create an AI-powered agent inside Settings that understands pure language and adjustments related undoable settings seamlessly. We aimed to combine this agent into the prevailing search field for a easy consumer expertise, requiring ultra-low latency for quite a few potential settings. After testing varied fashions, Phi LoRA initially met precision objectives however was too massive to fulfill latency targets. Mu, with the appropriate traits, required task-specific tuning for optimum efficiency in Home windows Settings.
Whereas baseline Mu on this state of affairs excelled by way of efficiency and energy footprint, it incurred a 2x precision drop utilizing the identical knowledge with none fine-tuning. To shut the hole, we scaled coaching to three.6M samples (1300x) and expanded from roughly 50 settings to a whole lot of settings. By using artificial approaches for automated labelling, immediate tuning with metadata, numerous phrasing, noise injection and good sampling, the Mu fine-tune used for Settings Agent efficiently met our high quality goals. The Mu mannequin fine-tune achieved response occasions of underneath 500 milliseconds, aligning with our objectives for a responsive and dependable agent in Settings that scaled to a whole lot of settings. The beneath picture exhibits how the expertise is built-in with an instance displaying the mapping from a pure use language question to a Settings motion being surfaced by the UI.
 Screenshot demonstrating the agent in Settings
Screenshot demonstrating the agent in Settings
To additional tackle the problem of quick and ambiguous consumer queries, we curated a various analysis set combining actual consumer inputs, artificial queries and customary settings, making certain the mannequin might deal with a variety of eventualities successfully. We noticed that the mannequin carried out greatest on multi-word queries that conveyed clear intent, versus quick or partial-word inputs, which frequently lack enough context for correct interpretation. To handle this hole, the agent in Settings is built-in into the Settings search field, enabling quick queries that don’t meet the multi-word threshold to proceed to floor lexical and semantic search ends in the search field, whereas permitting multi-word queries to floor the agent to return excessive precision actionable responses.
Managing the intensive array of Home windows settings posed its personal challenges, significantly with overlapping functionalities. As an example, even a easy question like “Improve brightness” might confer with a number of settings adjustments – if a consumer has twin displays, does that imply growing brightness to the first monitor or a secondary monitor?
To handle this, we refined our coaching knowledge to prioritize essentially the most used settings as we proceed to refine the expertise for extra advanced duties.
What’s forward
We welcome suggestions from customers within the Home windows Insiders program as we proceed to refine the expertise for the agent in Settings.
As we’ve shared in our earlier blogs, these breakthroughs wouldn’t be potential with out the assist of efforts from the Utilized Science Group and our companion groups in WAIIA and WinData that contributed to this work, together with: Adrian Bazaga, Archana Ramesh, Carol Ke, Chad Voegele, Cong Li, Daniel Rings, David Kolb, Eric Carter, Eric Sommerlade, Ivan Razumenic, Jana Shen, John Jansen, Joshua Elsdon, Karthik Sudandraprakash, Karthik Vijayan, Kevin Zhang, Leon Xu, Madhvi Mishra, Mathew Salvaris, Milos Petkovic, Patrick Derks, Prateek Punj, Rui Liu, Sunando Sengupta, Tamara Turnadzic, Teo Sarkic, Tingyuan Cui, Xiaoyan Hu, Yuchao Dai.

{kind=link}