



Unlock sooner, environment friendly reasoning with Phi-4-mini-flash-reasoning—optimized for edge, cellular, and real-time purposes.
Cutting-edge structure redefines velocity for reasoning fashions
Microsoft is worked up to unveil a brand new version to the Phi mannequin household: Phi-4-mini-flash-reasoning. Goal-built for eventualities the place compute, reminiscence, and latency are tightly constrained, this new mannequin is engineered to deliver superior reasoning capabilities to edge gadgets, cellular purposes, and different resource-constrained environments. This new mannequin follows Phi-4-mini, however is constructed on a brand new hybrid structure, that achieves as much as 10 occasions larger throughput and a 2 to three occasions common discount in latency, enabling considerably sooner inference with out sacrificing reasoning efficiency. Able to energy actual world options that demand effectivity and suppleness, Phi-4-mini-flash-reasoning is out there on Azure AI Foundry, NVIDIA API Catalogand Hugging Face at the moment.
Azure AI Foundry
Create with out boundaries—Azure AI Foundry has the whole lot that you must design, customise, and handle AI purposes and brokers
Effectivity with out compromise
Phi-4-mini-flash-reasoning balances math reasoning capability with effectivity, making it probably appropriate for instructional purposes, real-time logic-based purposes, and extra.
Much like its predecessor, Phi-4-mini-flash-reasoning is a 3.8 billion parameter open mannequin optimized for superior math reasoning. It helps a 64K token context size and is fine-tuned on high-quality artificial knowledge to ship dependable, logic-intensive efficiency deployment.
What’s new?
On the core of Phi-4-mini-flash-reasoning is the newly launched decoder-hybrid-decoder structure, SambaY, whose central innovation is the Gated Reminiscence Unit (GMU), a easy but efficient mechanism for sharing representations between layers. The structure features a self-decoder that mixes Mamba (a State Area Mannequin) and Sliding Window Consideration (SWA), together with a single layer of full consideration. The structure additionally includes a cross-decoder that interleaves costly cross-attention layers with the brand new, environment friendly GMUs. This new structure with GMU modules drastically improves decoding effectivity, boosts long-context retrieval efficiency and allows the structure to ship distinctive efficiency throughout a variety of duties.
Key advantages of the SambaY structure embrace:
Enhanced decoding effectivity.
Preserves linear prefiling time complexity.
Elevated scalability and enhanced lengthy context efficiency.
As much as 10 occasions larger throughput.
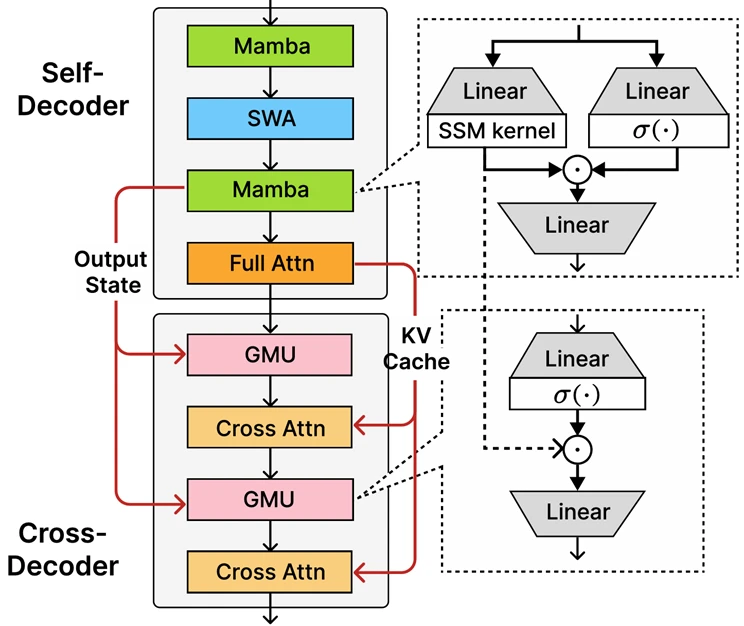 Our decoder-hybrid-decoder structure taking Samba (RLL+25) because the self-decoder. Gated Reminiscence Items (GMUs) are interleaved with the cross-attention layers within the cross-decoder to scale back the decoding computation complexity. As in YOCO (SDZ+24), the complete consideration layer solely computes the KV cache in the course of the prefilling with the self-decoder, resulting in linear computation complexity for the prefill stage.
Our decoder-hybrid-decoder structure taking Samba (RLL+25) because the self-decoder. Gated Reminiscence Items (GMUs) are interleaved with the cross-attention layers within the cross-decoder to scale back the decoding computation complexity. As in YOCO (SDZ+24), the complete consideration layer solely computes the KV cache in the course of the prefilling with the self-decoder, resulting in linear computation complexity for the prefill stage.
Phi-4-mini-flash-reasoning benchmarks
Like all fashions within the Phi household, Phi-4-mini-flash-reasoning is deployable on a single GPU, making it accessible for a broad vary of use circumstances. Nonetheless, what units it aside is its architectural benefit. This new mannequin achieves considerably decrease latency and better throughput in comparison with Phi-4-mini-reasoning, significantly in long-context technology and latency-sensitive reasoning duties.
This makes Phi-4-mini-flash-reasoning a compelling possibility for builders and enterprises seeking to deploy clever programs that require quick, scalable, and environment friendly reasoning—whether or not on premises or on-device.
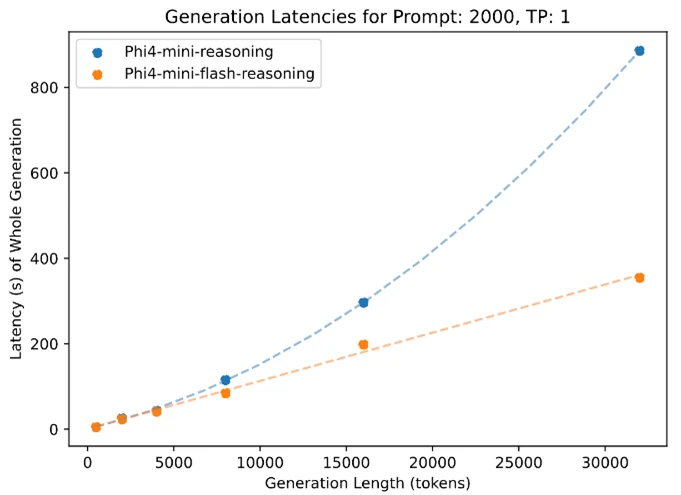
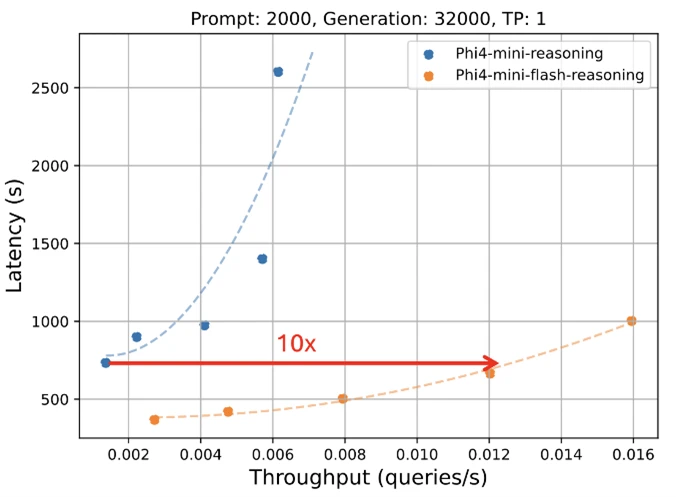 The highest plot reveals inference latency as a operate of technology size, whereas the underside plot illustrates how inference latency varies with throughput. Each experiments have been carried out utilizing the vLLM inference framework on a single A100-80GB GPU with tensor parallelism (TP) set to 1.
The highest plot reveals inference latency as a operate of technology size, whereas the underside plot illustrates how inference latency varies with throughput. Each experiments have been carried out utilizing the vLLM inference framework on a single A100-80GB GPU with tensor parallelism (TP) set to 1.
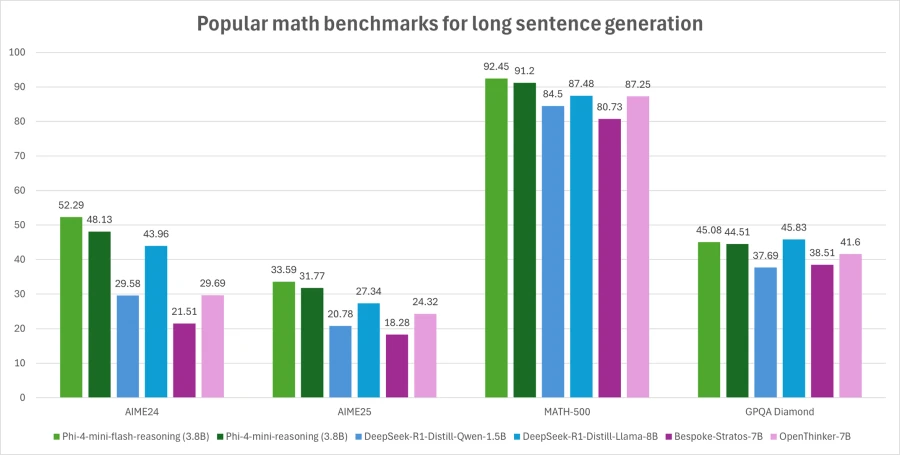 A extra correct analysis was used the place Go@1 accuracy is averaged over 64 samples for AIME24/25 and eight samples for Math500 and GPQA Diamond. On this graph, Phi-4-mini-flash-reasoning outperforms Phi-4-mini-reasoning and is best than fashions twice its measurement.
A extra correct analysis was used the place Go@1 accuracy is averaged over 64 samples for AIME24/25 and eight samples for Math500 and GPQA Diamond. On this graph, Phi-4-mini-flash-reasoning outperforms Phi-4-mini-reasoning and is best than fashions twice its measurement.
What are the potential use circumstances?
Because of its decreased latency, improved throughput, and give attention to math reasoning, the mannequin is right for:
Adaptive studying platforms, the place real-time suggestions loops are important.
On-device reasoning assistants, resembling cellular research aids or edge-based logic brokers.
Interactive tutoring programs that dynamically regulate content material problem based mostly on a learner’s efficiency.
Its power in math and structured reasoning makes it particularly priceless for schooling know-how, light-weight simulations, and automatic evaluation instruments that require dependable logic inference with quick response occasions.
Builders are inspired to attach with friends and Microsoft engineers by the Microsoft Developer Discord neighborhood to ask questions, share suggestions, and discover real-world use circumstances collectively.
Microsoft’s dedication to reliable AI
Organizations throughout industries are leveraging Azure AI and Microsoft 365 Copilot capabilities to drive progress, enhance productiveness, and create value-added experiences.
We’re dedicated to serving to organizations use and construct AI that’s reliablethat means it’s safe, personal, and secure. We deliver finest practices and learnings from many years of researching and constructing AI merchandise at scale to supply industry-leading commitments and capabilities that span our three pillars of safety, privateness, and security. Reliable AI is simply doable while you mix our commitments, resembling our Safe Future Initiative and our accountable AI ruleswith our product capabilities to unlock AI transformation with confidence.
Phi fashions are developed in accordance with Microsoft AI rules: accountability, transparency, equity, reliability and security, privateness and safety, and inclusiveness.
The Phi mannequin household, together with Phi-4-mini-flash-reasoning, employs a sturdy security post-training technique that integrates Supervised Advantageous-Tuning (SFT), Direct Choice Optimization (DPO), and Reinforcement Studying from Human Suggestions (RLHF). These methods are utilized utilizing a mixture of open-source and proprietary datasets, with a powerful emphasis on making certain helpfulness, minimizing dangerous outputs, and addressing a broad vary of security classes. Builders are inspired to use accountable AI finest practices tailor-made to their particular use circumstances and cultural contexts.
Learn the mannequin card to be taught extra about any threat and mitigation methods.

{kind=link}