



Are you incurring important cross Availability Zone visitors prices when operating an Apache Kafka shopper in containerized environments on Amazon Elastic Kubernetes Service (Amazon EKS) that eat knowledge from Amazon Managed Streaming for Apache Kafka (Amazon MSK) subjects?
In case you’re not acquainted with Apache Kafka’s rack consciousness characteristic, we strongly suggest beginning with the weblog put up on how you can Cut back community visitors prices of your Amazon MSK customers with rack consciousness for an in-depth rationalization of the characteristic and the way Amazon MSK helps it.
Though the answer described in that put up makes use of an Amazon Elastic Compute Cloud (Amazon EC2) occasion deployed in a single Availability Zone to eat messages from an Amazon MSK subject, trendy cloud-native architectures demand extra dynamic and scalable approaches. Amazon EKS has emerged as a number one platform for deploying and managing distributed purposes. The dynamic nature of Kubernetes introduces distinctive implementation challenges in comparison with static shopper deployments. On this put up, we stroll you thru an answer for implementing rack consciousness in shopper purposes which can be dynamically deployed throughout a number of Availability Zones utilizing Amazon EKS.
Right here’s a fast recap of some key Apache Kafka terminology from the referenced weblog. An Apache Kafka shopper shopper will register to learn in opposition to a subject. A subject is the logical knowledge construction that Apache Kafka organizes knowledge into. A subject is segmented right into a single or many partitions. Partitions are the unit of parallelism in Apache Kafka. Amazon MSK offers excessive availability by replicating every partition of a subject throughout brokers in several Availability Zones. As a result of there are replicas of every partition that reside throughout the completely different brokers that make up your MSK cluster, Amazon MSK additionally tracks whether or not a duplicate partition is in sync with the latest knowledge for that partition. This implies there’s one partition that Amazon MSK acknowledges as containing probably the most up-to-date knowledge, and this is called the chief partition. The gathering of replicated partitions known as in-sync replicas. This listing of in-sync replicas is used internally when the cluster must elect a brand new chief partition if the present chief have been to grow to be unavailable.
When shopper purposes learn from a subject, the Apache Kafka protocol facilitates a community trade to find out which dealer at present has the chief partition that the buyer must learn from. Which means the buyer might be instructed to learn from a dealer in a special Availability Zone than itself, resulting in cross-zone visitors cost in your AWS account. To assist optimize this value, Amazon MSK helps the rack consciousness characteristic, utilizing which purchasers can ask an Amazon MSK cluster to offer a duplicate partition to learn from, throughout the identical Availability Zone because the shopper, even when it isn’t the present chief partition. The cluster accomplishes this by checking for an in-sync reproduction on a dealer throughout the identical Availability Zone as the buyer.
The problem with Kafka purchasers on Amazon EKS
In Amazon EKS, the underlying items of computes are EC2 situations which can be abstracted as Kubernetes nodes. The nodes are organized into node teams for ease of administration, scaling, and grouping of purposes on sure EC2 occasion varieties. As a greatest follow for resilience, the nodes in a node group are unfold throughout a number of Availability Zones. Amazon EKS makes use of the underlying Amazon EC2 metadata concerning the Availability Zone that it’s positioned in, and it injects that info into the node’s metadata throughout node configuration. Specifically, the Availability Zone (AZ ID) is injected into the node metadata.
When an software is deployed in a Kubernetes Pod on Amazon EKS, it goes by a strategy of binding to a node that meets the pod’s necessities. As proven within the following diagram, while you deploy shopper purposes on Amazon EKS, the pod for the appliance will be sure to a node with accessible capability in any Availability Zone. Additionally, the pod doesn’t routinely inherit the Availability Zone info from the node that it’s sure to, a bit of data crucial for rack consciousness. The next structure diagram illustrates Kafka customers operating on Amazon EKS with out rack consciousness.
To set the shopper configuration for rack consciousness, the pod must know what Availability Zone it’s positioned in, dynamically, as it’s sure to a node. Throughout its lifecycle, the identical pod will be evicted from the node it was sure to beforehand and moved to a node in a special Availability Zone, if the matching standards allow that. Making the pod conscious of its Availability Zone dynamically units the rack consciousness parameter shopper.rack in the course of the initialization of the appliance container that’s encapsulated within the pod.
After rack consciousness is enabled on the MSK cluster, what occurs if the dealer in the identical Availability Zone because the shopper (hosted on Amazon EKS or elsewhere) turns into unavailable? The Apache Kafka protocol is designed to assist a distributed knowledge storage system. Assuming prospects comply with the most effective follow of implementing a replication issue > 1, Apache Kafka can dynamically reroute the buyer shopper to the subsequent accessible in-sync reproduction on a special dealer. This resilience stays constant even after implementing nearest reproduction fetching, or rack consciousness. Enabling rack consciousness optimizes the networking trade to favor a partition throughout the identical Availability Zone, nevertheless it doesn’t compromise the buyer’s capacity to function if the closest reproduction is unavailable.
On this put up, we stroll you thru an instance of how you can use the Kubernetes metadata label, topology.k8s.aws/zone-id, assigned to every node by Amazon EKS, and use an open supply coverage engine, Kyverno, to deploy a coverage that mutates the pods which can be within the binding state to dynamically inject the node’s AZ ID into the pod’s metadata as an annotation, as depicted within the following diagram. This annotation, in flip, is utilized by the container to create an surroundings variable that’s assigned the pod’s annotated AZ ID info. The surroundings variable is then used within the container postStart lifecycle hook to generate the Kafka shopper configuration file with rack consciousness setting. The next structure diagram illustrates Kafka customers operating on Amazon EKS with rack consciousness.
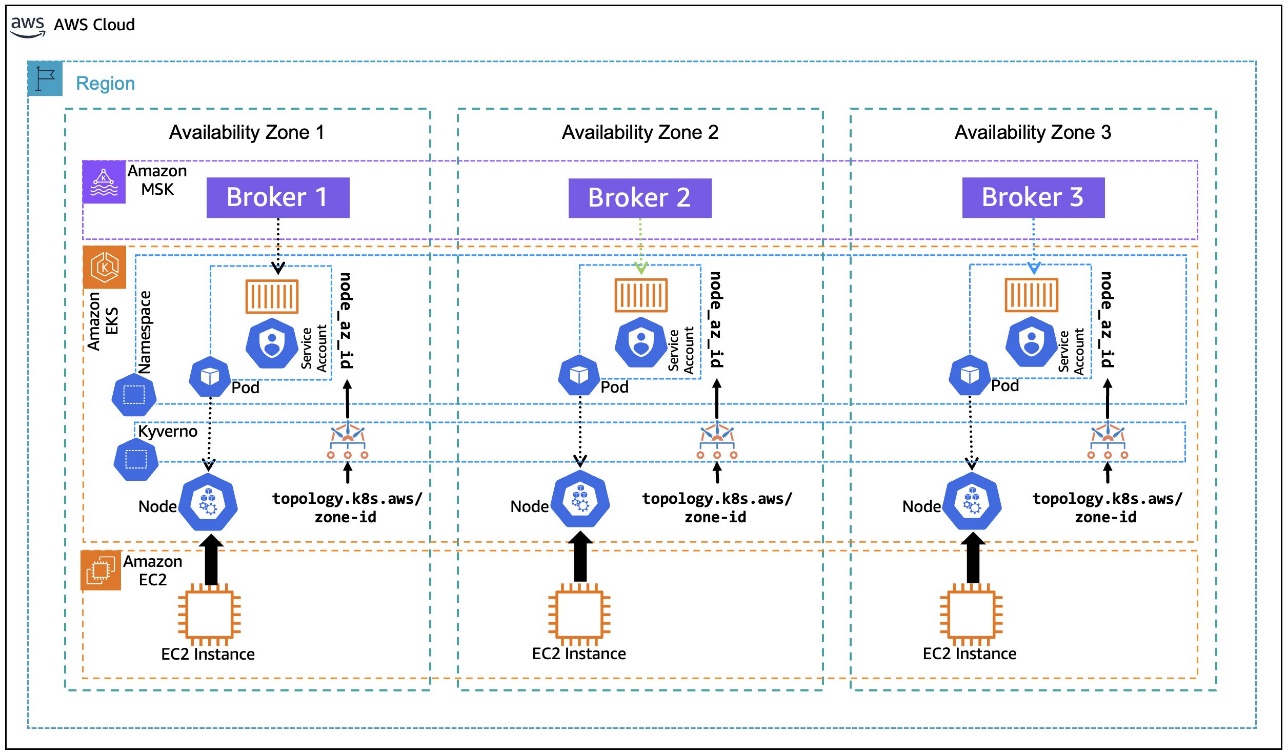
Resolution Walkthrough
Stipulations
For this walkthrough, we use AWS CloudShell to run the scripts which can be supplied inline as you progress. For a clean expertise, earlier than getting began, make certain to have kubectl and eksctl put in and configured within the AWS CloudShell surroundings, following the set up directions for Linux (amd64). Helm can be required to be set up on AWS CloudShell, utilizing the directions for Linux.
Additionally, test if the envsubst device is put in in your CloudShell surroundings by invoking:
If the device isn’t put in, you’ll be able to set up it utilizing the command:
sudo dnf -y set up gettext-devel
We additionally assume you have already got an MSK cluster deployed in an Amazon Digital Non-public Cloud (VPC) in three Availability Zones with the identify MSK-AZ-Conscious. On this walkthrough, we use AWS Identification and Entry Administration (IAM) authentication for shopper entry management to the MSK cluster. In case you’re utilizing a cluster in your account with a special identify, substitute the situations of MSK-AZ-Conscious within the directions.
We comply with the identical MSK cluster configuration talked about within the Rack Consciousness weblog talked about beforehand, with some modifications. (Make sure you’ve set reproduction.selector.class = org.apache.kafka.frequent.reproduction.RackAwareReplicaSelector for the explanations mentioned there). In our configuration, we add one line: num.partitions = 6. Though not necessary, this ensures that subjects which can be routinely created can have a number of partitions to assist clearer demonstrations in subsequent sections.
Lastly, we use the Amazon MSK Information Generator with the next configuration:
{
“identify”: “msk-data-generator”,
“config”: {
“connector.class”: “com.amazonaws.mskdatagen.GeneratorSourceConnector”,
“genkp.MSK-AZ-Conscious-Matter.with”: “#{Web.uuid}”,
“genv.MSK-AZ-Conscious-Matter.product_id.with”: “#{quantity.number_between ‘101’,’200′}”,
“genv.MSK-AZ-Conscious-Matter.amount.with”: “#{quantity.number_between ‘1’,’5′}”,
“genv.MSK-AZ-Conscious-Matter.customer_id.with”: “#{quantity.number_between ‘1’,’5000′}”
}
}
Working the MSK Information Generator with this configuration will routinely create a six-partition subject named MSK-AZ-Conscious-Matter on our cluster for us, and it’ll push knowledge to that subject. To comply with together with the walkthrough, we suggest and assume that you simply deploy the MSK Information Generator to create the subject and populate it with simulated knowledge.
Create the EKS cluster
Step one is to put in an EKS cluster in the identical Amazon VPC subnets because the MSK cluster. You’ll be able to modify the identify of the MSK cluster by altering that surroundings variable MSK_CLUSTER_NAME in case your cluster is created with a special identify than instructed. You too can change the Amazon EKS cluster identify by altering EKS_CLUSTER_NAME.
The surroundings variables that we outline listed below are used all through the walkthrough.
The final step is to replace the kubeconfig with an entry for the EKS cluster:
AWS_ACCOUNT=$(aws sts get-caller-identity –output textual content –query Account)
export AWS_ACCOUNT
export AWS_REGION=${AWS_DEFAULT_REGION}
export MSK_CLUSTER_NAME=MSK-AZ-Conscious
export EKS_CLUSTER_NAME=EKS-AZ-Conscious
export EKS_CLUSTER_SIZE=3
export K8S_VERSION=1.32
export POD_ID_VERSION=1.3.5
MSK_BROKER_SG=$(aws kafka list-clusters
–query ‘ClusterInfoList(?ClusterName==`’${MSK_CLUSTER_NAME}’`).BrokerNodeGroupInfo.SecurityGroups’
–output textual content | xargs)
export MSK_BROKER_SG
MSK_BROKER_CLIENT_SUBNETS=$(aws kafka list-clusters
–query ‘ClusterInfoList(?ClusterName==`’${MSK_CLUSTER_NAME}’`).BrokerNodeGroupInfo.ClientSubnets’
–output textual content | xargs)
export MSK_BROKER_CLIENT_SUBNETS
VPC_ID=$(aws ec2 describe-subnets
–subnet-ids “$(echo “${MSK_BROKER_CLIENT_SUBNETS}” | reduce -d’ ‘ -f1)”
–query ‘Subnets(0).VpcId’
–output textual content)
export VPC_ID
EKS_SUBNETS=$(echo ${MSK_BROKER_CLIENT_SUBNETS} | sed ‘s/ +/,/g’)
export EKS_SUBNETS
# Create a minimal config file for encrypted node volumes
cat > eks-config.yaml << EOF
apiVersion: eksctl.io/v1alpha5
form: ClusterConfig
metadata:
identify: ${EKS_CLUSTER_NAME}
area: ${AWS_REGION}
model: “${K8S_VERSION}”
vpc:
id: “${VPC_ID}”
subnets:
public:
$(for subnet in ${MSK_BROKER_CLIENT_SUBNETS}; do
AZ=$(aws ec2 describe-subnets –subnet-ids “$subnet” –query ‘Subnets(0).AvailabilityZone’ –output textual content)
echo ” $AZ: { id: $subnet }”
finished)
nodeGroups:
– identify: ng1
instanceType: m5.xlarge
desiredCapacity: ${EKS_CLUSTER_SIZE}
minSize: ${EKS_CLUSTER_SIZE}
maxSize: ${EKS_CLUSTER_SIZE}
securityGroups:
attachIDs: (“${MSK_BROKER_SG}”)
volumeSize: 100
volumeType: gp3
volumeEncrypted: true
EOF
eksctl create cluster -f eks-config.yaml
aws eks update-kubeconfig
–region “${AWS_REGION}”
–name ${EKS_CLUSTER_NAME}
Subsequent, that you must create an IAM coverage, MSK-AZ-Conscious-Coverage, to permit entry from the Amazon EKS pods to the MSK cluster. Be aware right here that we’re utilizing MSK-AZ-Conscious because the cluster identify.
Create a file, msk-az-aware-policy.json, with the IAM coverage template:
cat > msk-az-aware-policy.json << EOF
{
“Model”: “2012-10-17”,
“Assertion”: (
{
“Impact”: “Enable”,
“Motion”: (
“kafka-cluster:Join”,
“kafka-cluster:AlterCluster”,
“kafka-cluster:DescribeCluster”,
“kafka-cluster:DescribeClusterDynamicConfiguration”,
“kafka-cluster:AlterClusterDynamicConfiguration”
),
“Useful resource”: (
“arn:aws:kafka:${AWS_REGION}:${AWS_ACCOUNT}:cluster/${MSK_CLUSTER_NAME}/*”
)
},
{
“Impact”: “Enable”,
“Motion”: (
“kafka-cluster:*Matter*”,
“kafka-cluster:WriteData”,
“kafka-cluster:ReadData”
),
“Useful resource”: (
“arn:aws:kafka:${AWS_REGION}:${AWS_ACCOUNT}:subject/${MSK_CLUSTER_NAME}/*”
)
},
{
“Impact”: “Enable”,
“Motion”: (
“kafka-cluster:AlterGroup”,
“kafka-cluster:DescribeGroup”
),
“Useful resource”: (
“arn:aws:kafka:${AWS_REGION}:${AWS_ACCOUNT}:group/${MSK_CLUSTER_NAME}/*”
)
}
)
}
EOF
To create the IAM coverage, use the next command. It first replaces the placeholders within the coverage file with values from related surroundings variables, after which creates the IAM coverage:
envsubst < msk-az-aware-policy.json |
xargs -0 -I {} aws iam create-policy
–policy-name MSK-AZ-Conscious-Coverage
–policy-document {}
Configure EKS Pod Identification
Amazon EKS Pod Identification affords a simplified expertise for acquiring IAM permissions for pods on Amazon EKS. This requires putting in an add-on Amazon EKS Pod Identification Agent to the EKS cluster:
eksctl create addon
–cluster ${EKS_CLUSTER_NAME}
–name eks-pod-identity-agent
–version ${POD_ID_VERSION}
Verify that the add-on has been put in and its standing is ACTIVE and that the standing of all of the pods related to the add-on is Working.
eksctl get addon
–cluster ${EKS_CLUSTER_NAME}
–region “${AWS_REGION}”
–name eks-pod-identity-agent -o json
kubectl get pods
-n kube-system
-l app.kubernetes.io/occasion=eks-pod-identity-agent
After you’ve put in the add-on, that you must create a pod id affiliation between a Kubernetes service account and the IAM coverage created earlier:
eksctl create podidentityassociation
–namespace kafka-ns
–service-account-name kafka-sa
–role-name EKS-AZ-Conscious-Function
–permission-policy-arns arn:aws:iam::”${AWS_ACCOUNT}”:coverage/MSK-AZ-Conscious-Coverage
–cluster ${EKS_CLUSTER_NAME}
–region “${AWS_REGION}”
Set up Kyverno
Kyverno is an open supply coverage engine for Kubernetes that permits for validation, mutation, and technology of Kubernetes assets utilizing insurance policies written in YAML, thus simplifying the enforcement of safety and compliance necessities. You must set up Kyverno to dynamically inject metadata into the Amazon EKS pods as they enter the binding state to tell them of Availability Zone ID.
In AWS CloudShell, create a file named kyverno-values.yaml. This file defines the Kubernetes RBAC permissions for Kyverno’s Admission Controller to learn Amazon EKS node metadata as a result of the default Kyverno (v. 1.13 onwards) settings don’t permit this:
cat > kyverno-values.yaml << EOF
admissionController:
rbac:
clusterRole:
extraResources:
– apiGroups:
– “”
assets:
– “nodes”
verbs:
– get
– listing
– watch
EOF
After this file is created, you’ll be able to set up Kyverno utilizing helm and offering the values file created within the earlier step:
helm repo add kyverno https://kyverno.github.io/kyverno/
helm repo replace
helm set up kyverno kyverno/kyverno
-n kyverno
–create-namespace
–version 3.3.7
-f kyverno-values.yaml
Beginning with Kyverno v 1.13, the Admission Controller is configured to disregard the AdmissionReview requests for pods in binding state. This must be modified by enhancing the Kyverno ConfigMap:
kubectl -n kyverno edit configmap kyverno
The kubectl edit command makes use of the default editor configured in your surroundings (in our case Linux VIM).
This can open the ConfigMap in a textual content editor.
As highlighted within the following screenshot, (Pod/binding,*,*) must be faraway from the resourceFilters subject for the Kyverno Admission Controller to course of AdmissionReview requests for pods in binding state.
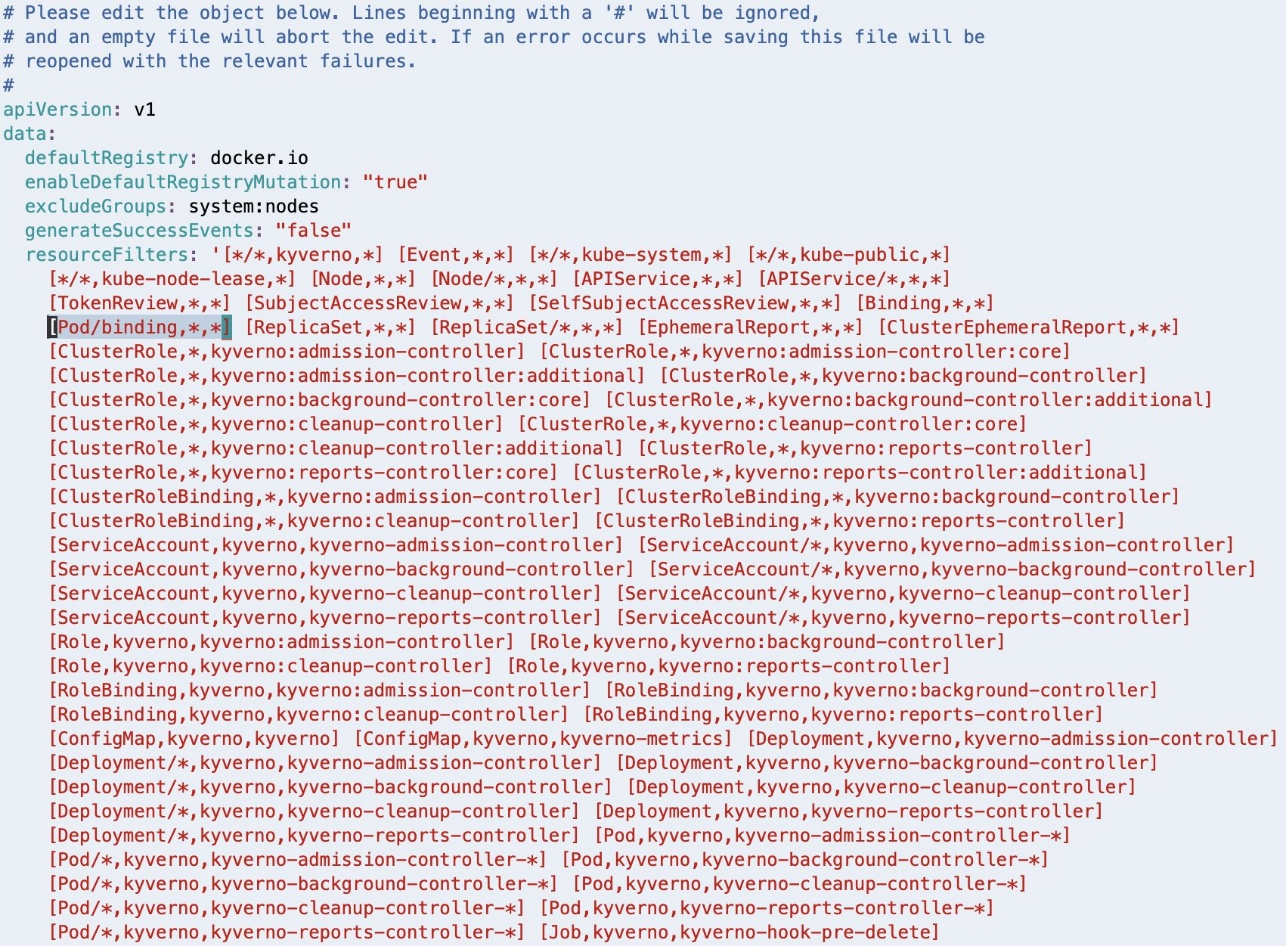
If Linux VIM is your default editor, you’ll be able to delete the entry utilizing VIM command 18x, which means delete (or reduce) 18 characters from the present cursor place. Save the modified configuration utilizing the VIM command :wq, which means write (or save) the file and give up.
After deleting, the resourceFilters subject ought to look much like the next screenshot.
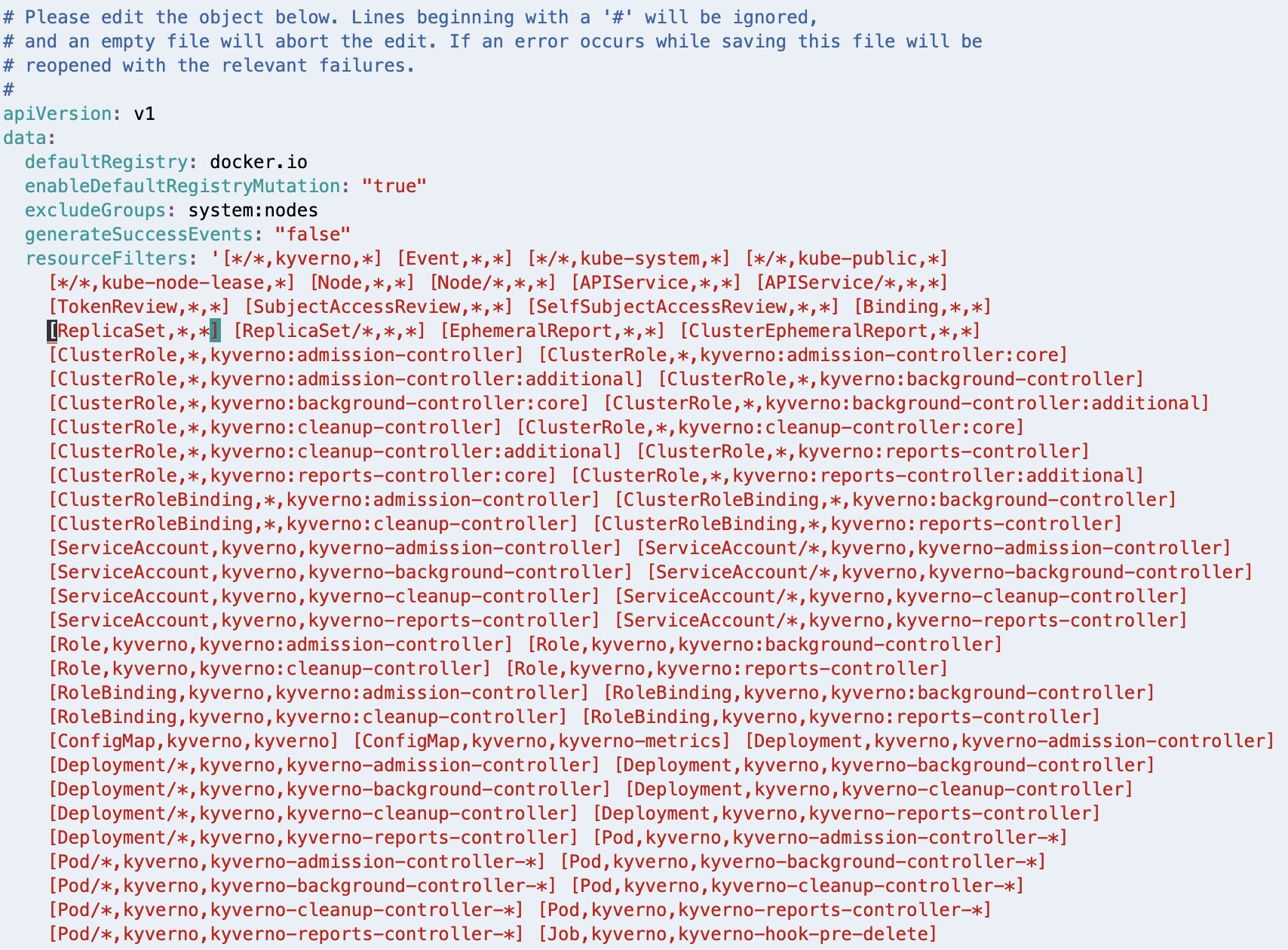
If in case you have a special editor configured in your surroundings, comply with the suitable steps to realize the same final result.
Configure Kyverno coverage
You must configure the coverage that can make the pods rack conscious. This coverage is tailored from the instructed method within the Kyverno weblog put up, Assigning Node Metadata to Pods. Create a brand new file with the identify kyverno-inject-node-az-id.yaml:
cat > kyverno-inject-node-az-id.yaml << EOF
apiVersion: kyverno.io/v2beta1
form: ClusterPolicy
metadata:
identify: inject-node-az-id
spec:
background: false
guidelines:
– identify: inject-node-az-id
match:
any:
– assets:
sorts:
– Pod/binding
context:
– identify: node
variable:
jmesPath: request.object.goal.identify
default: ”
– identify: node_az_id
apiCall:
urlPath: “/api/v1/nodes/{{node}}”
jmesPath: “metadata.labels.”topology.k8s.aws/zone-id” || ’empty'”
mutate:
patchStrategicMerge:
metadata:
annotations:
node_az_id: “{{ node_az_id }}”
EOF
It instructs Kyverno to look at for pods in binding state. After Kyverno receives the AdmissionReview request for a pod, it units the variable node to the identify of the node to which the pod is being sure. It additionally units one other variable node_az_id to the Availability Zone ID by calling the Kubernetes API /api/v1/nodes/node to get the node metadata label topology.k8s.aws/zone-id. Lastly, it defines a mutate rule to inject the obtained AZ ID into the pod’s metadata as an annotation node_az_id.
After you’ve created the file, apply the coverage utilizing the next command:
kubectl apply -f kyverno-inject-node-az-id.yaml
Deploy a pod with out rack consciousness
Now let’s visualize the issue assertion. To do that, connect with one of many EKS pods and test the way it interacts with the MSK cluster while you run a Kafka shopper from the pod.
First, get the bootstrap string of the MSK cluster. Search for the Amazon Useful resource Names (ARNs) of the MSK cluster:
MSK_CLUSTER_ARN=$(
aws kafka list-clusters
–query ‘ClusterInfoList(?ClusterName==`’${MSK_CLUSTER_NAME}’`).ClusterArn’
–output textual content)
export MSK_CLUSTER_ARN
Utilizing the cluster ARN, you will get the bootstrap string with the next command:
BOOTSTRAP_SERVER_LIST=$(
aws kafka get-bootstrap-brokers
–cluster-arn “${MSK_CLUSTER_ARN}”
–query ‘BootstrapBrokerStringSaslIam’
–output textual content)
export BOOTSTRAP_SERVER_LIST
Create a brand new file named kafka-no-az.yaml:
cat > kafka-no-az.yaml << EOF
apiVersion: v1
form: Namespace
metadata:
identify: kafka-ns
—
apiVersion: v1
form: ServiceAccount
metadata:
identify: kafka-sa
namespace: kafka-ns
automountServiceAccountToken: false
—
apiVersion: apps/v1
form: Deployment
metadata:
identify: kafka-no-az
namespace: kafka-ns
labels:
app: kafka-no-az
annotations:
node_az_id: ”
spec:
replicas: 3
selector:
matchLabels:
app: kafka-no-az
template:
metadata:
labels:
app: kafka-no-az
spec:
serviceAccountName: kafka-sa
containers:
– picture: bitnami/kafka:3.8.0
identify: kafka-no-az
command: (“/bin/sh”, “-ec”, “whereas :; do echo ‘.’; sleep 5 ; finished”)
env:
– identify: BootstrapServerString
worth: ${BOOTSTRAP_SERVER_LIST}
– identify: MSK_TOPIC
worth: “MSK-AZ-Conscious-Matter”
– identify: KAFKA_HOME
worth: /decide/bitnami/kafka
– identify: KAFKA_BIN
worth: /decide/bitnami/kafka/bin
– identify: KAFKA_CONFIG
worth: /decide/bitnami/kafka/config
– identify: KAFKA_LIBS
worth: /decide/bitnami/kafka/libs
– identify: KAFKA_LOG4J_OPTS
worth: “-Dlog4j.configuration=file:/decide/bitnami/kafka/config/log4j.properties”
lifecycle:
postStart:
exec:
command:
– “sh”
– “-c”
– |
export KAFKA_HOME=/decide/bitnami/kafka
export KAFKA_BIN=${KAFKA_HOME}/bin
export KAFKA_CONFIG=${KAFKA_HOME}/config
cat > ${KAFKA_CONFIG}/shopper.properties << EOF1
safety.protocol=SASL_SSL
sasl.mechanism=AWS_MSK_IAM
sasl.jaas.config=software program.amazon.msk.auth.iam.IAMLoginModule required;
sasl.shopper.callback.handler.class=software program.amazon.msk.auth.iam.IAMClientCallbackHandler
EOF1
cat >> ${KAFKA_CONFIG}/log4j.properties << EOF2
#
# Allow logging of Kafka Shopper to stderr
#
log4j.rootLogger=WARN, stderr
log4j.logger.org.apache.kafka.purchasers.shopper.internals.AbstractFetch=DEBUG
log4j.appender.stderr=org.apache.log4j.ConsoleAppender
log4j.appender.stderr.structure=org.apache.log4j.PatternLayout
log4j.appender.stderr.structure.ConversionPattern=(%d) %p %m (%c)%n
log4j.appender.stderr.Goal=System.err
EOF2
cd ${KAFKA_HOME}/libs
/usr/bin/curl -sS -L https://github.com/aws/aws-msk-iam-auth/releases/obtain/v2.2.0/aws-msk-iam-auth-2.2.0-all.jar –output ${KAFKA_LIBS}/aws-msk-iam-auth-2.2.0-all.jar
EOF
This pod manifest doesn’t make use of the Availability Zone ID injected into the metadata annotation and therefore doesn’t add shopper.rack to the shopper.properties configuration.
Deploy the pods utilizing the next command:
kubectl apply -f kafka-no-az.yaml
Run the next command to verify that the pods have been deployed and are within the Working state:
kubectl -n kafka-ns get pods
Choose a pod id from the output of the earlier command, and connect with it utilizing:
kubectl -n kafka-ns exec -it POD_ID — sh
Run the Kafka shopper:
“${KAFKA_BIN}”/kafka-console-consumer.sh
–bootstrap-server “${BootstrapServerString}”
–consumer.config “${KAFKA_CONFIG}”/shopper.properties
–topic “${MSK_TOPIC}”
–from-beginning /tmp/non-rack-aware-consumer.log 2>&1 &
This command will dump all of the ensuing logs into the file, non-rack-aware-consumer.log. There’s plenty of info in these logs, and we encourage you to open them and take a deeper look. Subsequent, look at the EKS pod in motion. To do that, run the next command to tail the file to view fetch request outcomes to the MSK cluster. You’ll discover a handful of significant logs to overview as the buyer entry numerous partitions of the Kafka subject:
grep -E “DEBUG.*Added read_uncommitted fetch request for partition MSK-AZ-Conscious-Matter-(0-9)+” /tmp/rack-aware-consumer.log | tail -5
Observe your log output, which ought to look much like the next:
(2025-03-12 23:59:05,308) DEBUG (Shopper clientId=console-consumer, groupId=console-consumer-24102) Added read_uncommitted fetch request for partition MSK-AZ-Conscious-Matter-3 at place FetchPosition{offset=100, offsetEpoch=Non-compulsory(0), currentLeader=LeaderAndEpoch{chief=Non-compulsory(b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 2 rack: use1-az6)), epoch=0}} to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 2 rack: use1-az6) (org.apache.kafka.purchasers.shopper.internals.AbstractFetch)
(2025-03-12 23:59:05,308) DEBUG (Shopper clientId=console-consumer, groupId=console-consumer-24102) Added read_uncommitted fetch request for partition MSK-AZ-Conscious-Matter-0 at place FetchPosition{offset=83, offsetEpoch=Non-compulsory(0), currentLeader=LeaderAndEpoch{chief=Non-compulsory(b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 2 rack: use1-az6)), epoch=0}} to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 2 rack: use1-az6) (org.apache.kafka.purchasers.shopper.internals.AbstractFetch)
(2025-03-12 23:59:05,542) DEBUG (Shopper clientId=console-consumer, groupId=console-consumer-24102) Added read_uncommitted fetch request for partition MSK-AZ-Conscious-Matter-5 at place FetchPosition{offset=100, offsetEpoch=Non-compulsory(0), currentLeader=LeaderAndEpoch{chief=Non-compulsory(b-1.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 1 rack: use1-az4)), epoch=0}} to node b-1.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 1 rack: use1-az4) (org.apache.kafka.purchasers.shopper.internals.AbstractFetch)
(2025-03-12 23:59:05,542) DEBUG (Shopper clientId=console-consumer, groupId=console-consumer-24102) Added read_uncommitted fetch request for partition MSK-AZ-Conscious-Matter-2 at place FetchPosition{offset=107, offsetEpoch=Non-compulsory(0), currentLeader=LeaderAndEpoch{chief=Non-compulsory(b-1.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 1 rack: use1-az4)), epoch=0}} to node b-1.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 1 rack: use1-az4) (org.apache.kafka.purchasers.shopper.internals.AbstractFetch)
(2025-03-12 23:59:05,720) DEBUG (Shopper clientId=console-consumer, groupId=console-consumer-24102) Added read_uncommitted fetch request for partition MSK-AZ-Conscious-Matter-4 at place FetchPosition{offset=84, offsetEpoch=Non-compulsory(0), currentLeader=LeaderAndEpoch{chief=Non-compulsory(b-3.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 3 rack: use1-az2)), epoch=0}} to node b-3.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 3 rack: use1-az2) (org.apache.kafka.purchasers.shopper.internals.AbstractFetch)
(2025-03-12 23:59:05,720) DEBUG (Shopper clientId=console-consumer, groupId=console-consumer-24102) Added read_uncommitted fetch request for partition MSK-AZ-Conscious-Matter-1 at place FetchPosition{offset=85, offsetEpoch=Non-compulsory(0), currentLeader=LeaderAndEpoch{chief=Non-compulsory(b-3.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 3 rack: use1-az2)), epoch=0}} to node b-3.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 3 rack: use1-az2) (org.apache.kafka.purchasers.shopper.internals.AbstractFetch)
(2025-03-12 23:59:05,811) DEBUG (Shopper clientId=console-consumer, groupId=console-consumer-24102) Added read_uncommitted fetch request for partition MSK-AZ-Conscious-Matter-3 at place FetchPosition{offset=100, offsetEpoch=Non-compulsory(0), currentLeader=LeaderAndEpoch{chief=Non-compulsory(b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 2 rack: use1-az6)), epoch=0}} to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 2 rack: use1-az6) (org.apache.kafka.purchasers.shopper.internals.AbstractFetch)
(2025-03-12 23:59:05,811) DEBUG (Shopper clientId=console-consumer, groupId=console-consumer-24102) Added read_uncommitted fetch request for partition MSK-AZ-Conscious-Matter-0 at place FetchPosition{offset=83, offsetEpoch=Non-compulsory(0), currentLeader=LeaderAndEpoch{chief=Non-compulsory(b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 2 rack: use1-az6)), epoch=0}} to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 2 rack: use1-az6) (org.apache.kafka.purchasers.shopper.internals.AbstractFetch)
You’ve now linked to a selected pod within the EKS cluster and run a Kafka shopper to learn from the MSK subject with out rack consciousness. Do not forget that this pod is operating inside a single Availability Zone.
Reviewing the log output, you discover rack: values as use1-az2, use1-az4, and use1-az6 because the pod makes calls to completely different partitions of the subject. These rack values symbolize the Availability Zone IDs that our brokers are operating inside. Which means our EKS pod is creating networking connections to brokers throughout three completely different Availability Zones, which might be accruing networking prices in our account.
Additionally discover that you don’t have any approach to test which node, and subsequently Availability Zone, this EKS pod is operating in. You’ll be able to observe within the logs that it’s calling to MSK brokers in several Availability Zones, however there isn’t any approach to know which dealer is in the identical Availability Zone because the EKS pod you’ve linked to. Delete the deployment while you’re finished:
kubectl -n kafka-ns delete -f kafka-no-az.yaml
Deploy a pod with rack consciousness
Now that you’ve got skilled the buyer conduct with out rack consciousness, that you must inject the Availability Zone ID to make your pods rack-aware.
Create a brand new file named kafka-az-aware.yaml:
cat > kafka-az-aware.yaml << EOF
apiVersion: v1
form: Namespace
metadata:
identify: kafka-ns
—
apiVersion: v1
form: ServiceAccount
metadata:
identify: kafka-sa
namespace: kafka-ns
automountServiceAccountToken: false
—
apiVersion: apps/v1
form: Deployment
metadata:
identify: kafka-az-aware
namespace: kafka-ns
labels:
app: kafka-az-aware
annotations:
node_az_id: ”
spec:
replicas: 3
selector:
matchLabels:
app: kafka-az-aware
template:
metadata:
labels:
app: kafka-az-aware
spec:
serviceAccountName: kafka-sa
containers:
– picture: bitnami/kafka:3.8.0
identify: kafka-az-aware
command: (“/bin/sh”, “-ec”, “whereas :; do echo ‘.’; sleep 5 ; finished”)
env:
– identify: BootstrapServerString
worth: ${BOOTSTRAP_SERVER_LIST}
– identify: MSK_TOPIC
worth: “MSK-AZ-Conscious-Matter”
– identify: KAFKA_HOME
worth: /decide/bitnami/kafka
– identify: KAFKA_BIN
worth: /decide/bitnami/kafka/bin
– identify: KAFKA_CONFIG
worth: /decide/bitnami/kafka/config
– identify: KAFKA_LIBS
worth: /decide/bitnami/kafka/libs
– identify: KAFKA_LOG4J_OPTS
worth: “-Dlog4j.configuration=file:/decide/bitnami/kafka/config/log4j.properties”
– identify: NODE_AZ_ID
valueFrom:
fieldRef:
fieldPath: metadata.annotations(‘node_az_id’)
lifecycle:
postStart:
exec:
command:
– “sh”
– “-c”
– |
export KAFKA_HOME=/decide/bitnami/kafka
export KAFKA_BIN=${KAFKA_HOME}/bin
export KAFKA_CONFIG=${KAFKA_HOME}/config
cat > ${KAFKA_CONFIG}/shopper.properties << EOF1
safety.protocol=SASL_SSL
sasl.mechanism=AWS_MSK_IAM
sasl.jaas.config=software program.amazon.msk.auth.iam.IAMLoginModule required;
sasl.shopper.callback.handler.class=software program.amazon.msk.auth.iam.IAMClientCallbackHandler
EOF1
if ( $NODE_AZ_ID )
then
echo “shopper.rack=$NODE_AZ_ID” >> ${KAFKA_CONFIG}/shopper.properties
fi
cat >> ${KAFKA_CONFIG}/log4j.properties << EOF2
#
# Allow logging of Kafka Shopper to stderr
#
log4j.rootLogger=WARN, stderr
log4j.logger.org.apache.kafka.purchasers.shopper.internals.AbstractFetch=DEBUG
log4j.appender.stderr=org.apache.log4j.ConsoleAppender
log4j.appender.stderr.structure=org.apache.log4j.PatternLayout
log4j.appender.stderr.structure.ConversionPattern=(%d) %p %m (%c)%n
log4j.appender.stderr.Goal=System.err
EOF2
/usr/bin/curl -sS -L https://github.com/aws/aws-msk-iam-auth/releases/obtain/v2.2.0/aws-msk-iam-auth-2.2.0-all.jar –output ${KAFKA_LIBS}/aws-msk-iam-auth-2.2.0-all.jar
EOF
As you’ll be able to observe, the pod manifest defines an surroundings variable NODE_AZ_ID, assigning it the worth from the pod’s personal metadata annotation node_az_id that was injected by Kyverno. The manifest then makes use of the pod’s postStart lifecycle script so as to add shopper.rack into the shopper.properties configuration, setting it equal to the worth within the surroundings variable NODE_AZ_ID.
Deploy the pods utilizing the next command:
kubectl apply -f kafka-az-aware.yaml
Run the next command to verify that the pods have been deployed and are within the Working state:
kubectl -n kafka-ns get pods
Confirm that Availability Zone Ids have been injected into the pods
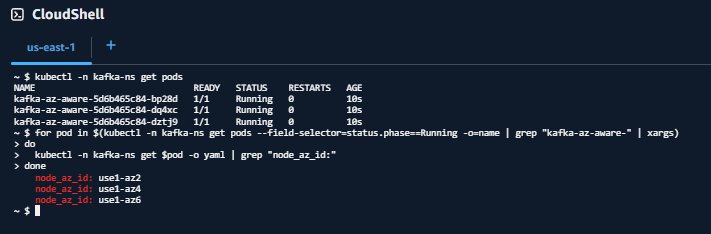
for pod in $(kubectl -n kafka-ns get pods –field-selector=standing.section==Working -o=identify | grep “pod/kafka-az-aware-” | xargs)
do
kubectl -n kafka-ns get “$pod” -o yaml | grep “node_az_id:”
finished
Your output ought to look much like:
node_az_id: use1-az2
node_az_id: use1-az4
node_az_id: use1-az6
Or:
Choose a pod id from the output of the get pods command and shell-in to it.
kubectl -n kafka-ns exec -it POD_ID — sh
The output of the get $pod command matches the order of outcomes from the get pods command. This matching will allow you to perceive what Availability Zone your pod is operating in so you’ll be able to evaluate it to log outputs later.
After you’ve linked to your pod, run the Kafka shopper:
“${KAFKA_BIN}”/kafka-console-consumer.sh
–bootstrap-server “${BootstrapServerString}”
–consumer.config “${KAFKA_CONFIG}”/shopper.properties
–topic “${MSK_TOPIC}”
–from-beginning /tmp/non-rack-aware-consumer.log 2>&1 &
Just like earlier than, this command will dump all of the ensuing logs into the file, rack-aware-consumer.log. You create a brand new file so there’s no overlap between the Kafka customers you’ve run. There’s plenty of info in these logs, and we encourage you to open them and take a deeper look. If you wish to see the rack consciousness of your EKS pod in motion, run the next command to tail the file to view fetch request outcomes to the MSK cluster. You’ll be able to observe a handful of significant logs to overview right here as the buyer entry numerous partitions of the Kafka subject:
grep -E “DEBUG.*Added read_uncommitted fetch request for partition MSK-AZ-Conscious-Matter-(0-9)+” /tmp/rack-aware-consumer.log | tail -5
Observe your log output, which ought to look much like the next:
(2025-03-13 00:47:51,695) DEBUG (Shopper clientId=console-consumer, groupId=console-consumer-86303) Added read_uncommitted fetch request for partition MSK-AZ-Conscious-Matter-5 at place FetchPosition{offset=527, offsetEpoch=Non-compulsory(0), currentLeader=LeaderAndEpoch{chief=Non-compulsory(b-1.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 1 rack: use1-az4)), epoch=0}} to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 2 rack: use1-az6) (org.apache.kafka.purchasers.shopper.internals.AbstractFetch)
(2025-03-13 00:47:51,695) DEBUG (Shopper clientId=console-consumer, groupId=console-consumer-86303) Added read_uncommitted fetch request for partition MSK-AZ-Conscious-Matter-4 at place FetchPosition{offset=509, offsetEpoch=Non-compulsory(0), currentLeader=LeaderAndEpoch{chief=Non-compulsory(b-3.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 3 rack: use1-az2)), epoch=0}} to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 2 rack: use1-az6) (org.apache.kafka.purchasers.shopper.internals.AbstractFetch)
(2025-03-13 00:47:51,695) DEBUG (Shopper clientId=console-consumer, groupId=console-consumer-86303) Added read_uncommitted fetch request for partition MSK-AZ-Conscious-Matter-3 at place FetchPosition{offset=527, offsetEpoch=Non-compulsory(0), currentLeader=LeaderAndEpoch{chief=Non-compulsory(b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 2 rack: use1-az6)), epoch=0}} to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 2 rack: use1-az6) (org.apache.kafka.purchasers.shopper.internals.AbstractFetch)
(2025-03-13 00:47:51,695) DEBUG (Shopper clientId=console-consumer, groupId=console-consumer-86303) Added read_uncommitted fetch request for partition MSK-AZ-Conscious-Matter-2 at place FetchPosition{offset=522, offsetEpoch=Non-compulsory(0), currentLeader=LeaderAndEpoch{chief=Non-compulsory(b-1.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 1 rack: use1-az4)), epoch=0}} to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 2 rack: use1-az6) (org.apache.kafka.purchasers.shopper.internals.AbstractFetch)
(2025-03-13 00:47:51,695) DEBUG (Shopper clientId=console-consumer, groupId=console-consumer-86303) Added read_uncommitted fetch request for partition MSK-AZ-Conscious-Matter-1 at place FetchPosition{offset=533, offsetEpoch=Non-compulsory(0), currentLeader=LeaderAndEpoch{chief=Non-compulsory(b-3.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 3 rack: use1-az2)), epoch=0}} to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 2 rack: use1-az6) (org.apache.kafka.purchasers.shopper.internals.AbstractFetch)
(2025-03-13 00:47:51,695) DEBUG (Shopper clientId=console-consumer, groupId=console-consumer-86303) Added read_uncommitted fetch request for partition MSK-AZ-Conscious-Matter-0 at place FetchPosition{offset=520, offsetEpoch=Non-compulsory(0), currentLeader=LeaderAndEpoch{chief=Non-compulsory(b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 2 rack: use1-az6)), epoch=0}} to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 2 rack: use1-az6) (org.apache.kafka.purchasers.shopper.internals.AbstractFetch)
For every log line, now you can observe two rack: values. The primary rack: worth reveals the present chief, the second rack: reveals the rack that’s getting used to fetch messages.
For instance, take a look at MSK-AZ-Conscious-Matter-5. The chief is recognized as rack: use1-az4, however the fetch request is shipped to use1-az6 as indicated by to node b-2.mskazaware.hxrzlh.c6.kafka.us-east-1.amazonaws.com:9098 (id: 2 rack: use1-az6) (org.apache.kafka.purchasers.shopper.internals.AbstractFetch)
You’ll discover one thing related in all different log strains. The fetch is all the time to the dealer in use1-az6, which maps to our expectation, given the pod we linked to was on this Availability Zone.
Congratulations! You’re consuming from the closest reproduction on Amazon EKS.
Clear Up
Delete the deployment when completed:
kubectl -n kafka-ns delete -f kafka-az-aware.yaml
To delete the EKS Pod Identification affiliation:
eksctl delete podidentityassociation
–cluster ${EKS_CLUSTER_NAME}
–namespace kafka-ns
–service-account-name kafka-sa
To delete the IAM coverage:
aws iam delete-policy
–policy-arn arn:aws:iam::”${AWS_ACCOUNT}”:coverage/MSK-AZ-Conscious-Coverage
To delete the EKS cluster:
eksctl delete cluster -n ${EKS_CLUSTER_NAME} –disable-nodegroup-eviction
In case you adopted together with this put up utilizing the Amazon MSK Information Generator, remember to delete your deployment so it’s not making an attempt to generate and ship knowledge after you delete the remainder of your assets.
Clear up will rely upon which deployment possibility you used. To learn extra concerning the deployment choices and the assets created for the Amazon MSK Information Generator, discuss with Getting Began within the GitHub repository.
Creating an MSK cluster was a prerequisite of this put up, and in the event you’d like to wash up the MSK cluster as effectively, you need to use the next command:
aws kafka delete-cluster –cluster-arn “${MSK_CLUSTER_ARN}”
There isn’t a extra value to utilizing AWS CloudShell, however in the event you’d prefer to delete your shell, discuss with the Delete a shell session house listing within the AWS CloudShell Consumer Information.
Conclusion
Apache Kafka nearest reproduction fetching, or rack consciousness, is a strategic cost-optimization method. By implementing it for Amazon MSK customers on Amazon EKS, you’ll be able to considerably cut back cross-zone visitors prices whereas sustaining sturdy, distributed streaming architectures. Open supply instruments equivalent to Kyverno can simplify advanced configuration challenges and drive significant financial savings.The answer we’ve demonstrated offers a strong, repeatable method to dynamically injecting Availability Zone info into Kubernetes pods, optimize Kafka shopper routing, and decrease cut back switch prices.
Further assets
To study extra about rack consciousness with Amazon MSK, discuss with Cut back community visitors prices of your Amazon MSK customers with rack consciousness.
Concerning the authors
 Austin Groeneveld is a Streaming Specialist Options Architect at Amazon Net Companies (AWS), based mostly within the San Francisco Bay Space. On this position, Austin is keen about serving to prospects speed up insights from their knowledge utilizing the AWS platform. He’s significantly fascinated by the rising position that knowledge streaming performs in driving innovation within the knowledge analytics house. Exterior of his work at AWS, Austin enjoys watching and enjoying soccer, touring, and spending high quality time together with his household.
Austin Groeneveld is a Streaming Specialist Options Architect at Amazon Net Companies (AWS), based mostly within the San Francisco Bay Space. On this position, Austin is keen about serving to prospects speed up insights from their knowledge utilizing the AWS platform. He’s significantly fascinated by the rising position that knowledge streaming performs in driving innovation within the knowledge analytics house. Exterior of his work at AWS, Austin enjoys watching and enjoying soccer, touring, and spending high quality time together with his household.
 Farooq Ashraf is a Senior Options Architect at AWS, specializing in SaaS, Generative AI, and MLOps. He’s keen about mixing multi-tenant SaaS ideas with Cloud companies to innovate scalable options for the digital enterprise, and has a number of weblog posts, and workshops to his credit score.
Farooq Ashraf is a Senior Options Architect at AWS, specializing in SaaS, Generative AI, and MLOps. He’s keen about mixing multi-tenant SaaS ideas with Cloud companies to innovate scalable options for the digital enterprise, and has a number of weblog posts, and workshops to his credit score.

{kind=link}