



Introduction: Logging Issues, Right here’s Why
Scaling from a couple of dozen jobs to a whole lot is difficult for a number of causes, considered one of which is observability. Observability is the power to know the system by analyzing elements corresponding to logs, metrics, and traces. That is simply as related for smaller information groups with only some pipelines to watch, and distributed computing engines like Spark could be difficult to reliably monitor, debug, and create mature escalation procedures.
Logging is arguably the only and most impactful of those observability elements. Clicking and scrolling by logs, one job run at a time, shouldn’t be scalable. It may be time-consuming, tough to parse, and infrequently requires subject-matter experience of the workflow. With out constructing mature logging requirements into your information pipelines, troubleshooting errors or job failures takes considerably longer, resulting in pricey outages, ineffective tiers of escalation, and alert fatigue.
On this weblog, we’ll stroll you thru:
Steps to interrupt away from fundamental print statements and arrange a correct logging framework.
When to configure the Spark log4j logs to make use of JSON format.
Why centralize cluster log storage for simple parsing and querying.
create a central AI/BI dashboard in Databricks that you would be able to arrange in your personal workspace for extra personalized log evaluation.
Key Architectural Issues
The next concerns are essential to bear in mind to tailor these logging suggestions to your group:
Logging Libraries
A number of logging libraries exist for each Python and Scala. Our examples use Log4j and the usual Python logging module.
Configuration for logging libraries or frameworks will probably be completely different, and it’s best to seek the advice of their respective documentation if utilizing a non-standard instrument.
Cluster Sorts
Examples on this weblog will focus totally on the next compute:
On the time of this writing, the next compute varieties have much less assist for log supply, though suggestions for logging frameworks nonetheless apply:
Lakeflow Declarative Pipelines (previously DLT): Solely helps occasion logs
Serverless Jobs: Doesn’t assist log supply
Serverless Notebooks: Doesn’t assist log supply
Knowledge Governance
Knowledge governance ought to lengthen to cluster logs, as logs could unintentionally expose delicate information. For instance, once you write logs to a desk, it’s best to contemplate which customers have entry to the desk and make the most of least privilege entry design.
We are going to exhibit easy methods to ship cluster logs to Unity Catalog volumes for easier entry management and lineage. Log supply to Volumes is in Public Preview and is barely supported on Unity Catalog-enabled compute with Normal entry mode or Devoted entry mode assigned to a person.
This characteristic shouldn’t be supported on compute with Devoted entry mode assigned to a bunch.
Technical Answer Breakdown
Standardization is vital to production-grade log observability.. Ideally, the answer ought to accommodate a whole lot and even hundreds of jobs/pipelines/clusters.
For the total implementation of this answer, please go to this repo right here: https://github.com/databricks-industry-solutions/watchtower
Making a Quantity for central log supply
First, we will create a Unity Catalog Quantity to be our central file storage for logs. We don’t suggest DBFS because it doesn’t present the identical stage of information governance. We suggest separating logs for every setting (e.g., dev, stage, prod) into completely different directories or volumes so entry could be managed extra granularly.
You may create this within the UI, inside a Databricks Asset Bundle (AWS | Azure | GCP), or in our case, with Terraform:
Please guarantee you may have the READ VOLUME and WRITE VOLUME permissions on the amount (AWS | Azure | GCP).
Configure Cluster log supply
Now that we’ve a central place to place our logs, we have to configure clusters to ship their logs into this vacation spot. To do that, configure compute log supply (AWS | Azure | GCP) on the cluster.
Once more, use the UI, Terraform, or different most well-liked technique; we are going to use Databricks Asset Bundles (YAML):
Upon working the cluster or job, inside a couple of minutes, we will browse to the Quantity within the Catalog Explorer and see the information arriving. You will note a folder with the cluster ID (i.e., 0614-174319-rbzrs7rq), then folders for every group of logs:
driver: Logs from the Driver node, which we’re most excited about.
executor: Logs from every Spark executor within the cluster.
eventlog: logs of occasions yow will discover within the “Occasion Log” tab of the cluster, corresponding to cluster beginning, cluster terminating, resizing, and many others.
init_scripts: This folder is generated if the cluster has init scripts, as ours does. Subfolders are created for every node within the cluster, after which stdout and stderr logs could be discovered for every init script that was executed on the node.
Implementing Requirements: Cluster Coverage
Workspace admins ought to implement commonplace configurations at any time when potential. This implies proscribing cluster creation entry, and giving customers a Cluster Coverage (AWS | Azure | GCP) with the cluster log configuration set to mounted values as proven under:
Setting these attributes to a “mounted” worth routinely configures the right Quantity vacation spot and prevents customers from forgetting or altering the property.
Now, as an alternative of explicitly configuring the cluster_log_conf in your asset bundle YAML, we will merely specify the cluster coverage ID to make use of:
Greater than only a print() assertion
Whereas print() statements could be helpful for fast debugging throughout growth, they fall brief in manufacturing environments for a number of causes:
Lack of construction: Print statements produce unstructured textual content, making it tough to parse, question, and analyze logs at scale.
Restricted context: They usually lack important contextual data like timestamps, log ranges (e.g., INFO, WARNING, ERROR), originating module, or job ID, that are essential for efficient troubleshooting.
Efficiency overhead: Extreme print statements can introduce efficiency overhead as they set off an analysis in Spark. Print statements additionally write instantly to plain output (stdout) with out buffering or optimized dealing with.
No management over verbosity: There isn’t any built-in mechanism to manage the verbosity of print statements, resulting in logs both being too noisy or inadequate intimately.
Correct logging frameworks, like Log4j for Scala/Java (JVM) or the built-in logging module for Python, resolve all these issues and are most well-liked in manufacturing. These frameworks allow us to outline log ranges or verbosity, output machine-friendly codecs like JSON and set versatile locations.
Please additionally word the distinction between stdout vs. stderr vs. log4j in Spark driver logs:
stdout: Normal Output buffer from the driving force node’s JVM. That is the place print() statements and normal output are written by default.
stderr: Normal Error buffer from the driving force node’s JVM. That is usually the place exceptions/stacktraces are written, and plenty of logging libraries additionally default to stderr.
log4j: Particularly filtered to log messages written with a log4j logger. You might even see these in messages in stderr as nicely.
Python
In Python, this includes importing the usual logging module, defining a JSON format, and setting your log stage.
As of Spark 4, or Databricks Runtime 17.0+, a simplified structured logger is constructed into PySpark: https://spark.apache.org/docs/newest/api/python/growth/logger.html. The next instance could be tailored to PySpark 4 by swapping the logger occasion for a pyspark.logger.PySparkLogger occasion.
A lot of this code is simply to format our Python log messages as JSON. JSON is semi-structured and simple to learn for each people and machines, which we’ll come to understand when ingesting and querying these logs later on this weblog. If we skipped this step, it’s possible you’ll end up counting on advanced, inefficient common expressions to guess at which a part of the message is the log stage versus a timestamp versus the message, and many others.
After all, that is pretty verbose to incorporate in each pocket book or Python package deal. To keep away from duplication, this boilerplate could also be packaged up as utility code and loaded to your jobs in a couple of methods:
Put the boilerplate code in a Python module on the workspace and use workspace file imports (AWS | Azure | GCP) to execute the code firstly of your primary notebooks.
Construct the boilerplate code right into a Python wheel file and cargo it onto the clusters as a Library (AWS | Azure | GCP).
Scala
The identical rules apply to Scala, however we are going to use Log4j as an alternative, or extra particularly, the SLF4j abstraction:
Once we view the Driver Logs within the UI, we will discover our INFO and WARN log messages below Log4j. It is because the default log stage is INFO, so the DEBUG and TRACE messages will not be written.

The Log4j logs will not be in JSON format, although! We’ll see easy methods to repair that subsequent.
Logging for Spark Structured Streaming
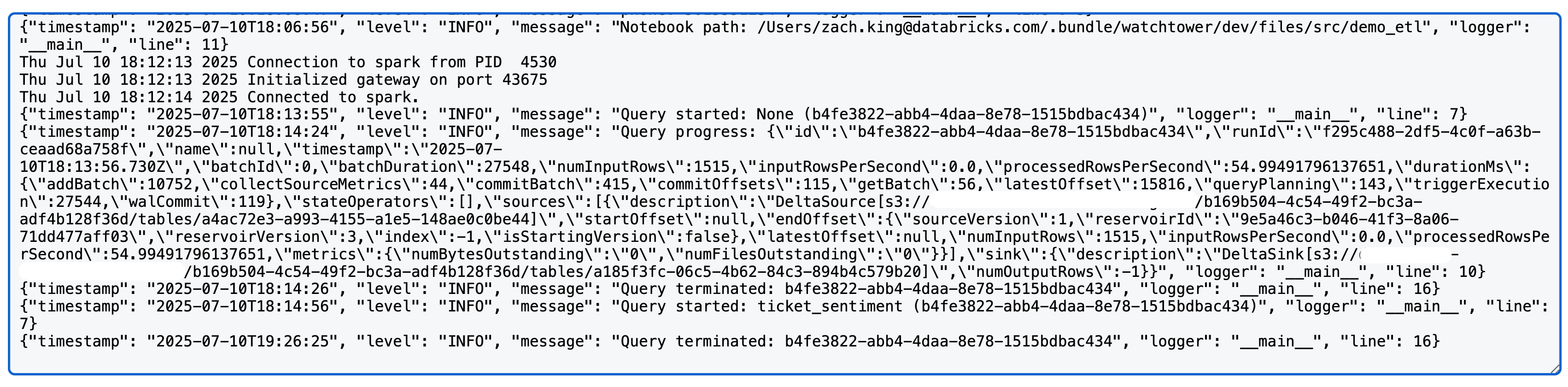
To seize helpful data for streaming jobs, corresponding to streaming supply and sink metrics and question progress, we will additionally implement the StreamingQueryListener from Spark.
Then register the question listener along with your Spark session:
Upon working a Spark structured streaming question, you’ll now see one thing like the next within the log4j logs (word: we use a Delta supply and sink on this case; detailed metrics could fluctuate by supply/sink):
Configuring the Spark Log4j Logs
Till now, we’ve solely affected our personal code’s logging. Nevertheless, wanting on the cluster’s Driver Logs, we will see many extra logs–the bulk, actually–are from Spark internals. Once we create Python or Scala loggers in our code, this doesn’t affect the Spark inner logs.
We are going to now overview easy methods to configure the Spark logs for the Driver node in order that they use commonplace JSON format that we will simply parse.
Log4j makes use of an area configuration file to manage formatting and log ranges, and we will modify this configuration utilizing a Cluster Init Script (AWS | Azure | GCP). Please word that previous to DBR 11.0, Log4j v1.x was used, which makes use of a Java Properties (log4j.properties) file. DBR 11.0+ makes use of Log4j v2.x which makes use of an XML (log4j2.xml) file as an alternative.
The default log4j2.xml file on Databricks driver nodes makes use of a PatternLayout for a fundamental log format:
We are going to change this to the JsonTemplateLayout utilizing the next init script:
This init script merely swaps out the PatternLayout for JsonTemplateLayout. Observe that init scripts execute on all nodes within the cluster, together with employee nodes; on this instance, we’re solely configuring the Driver logs for verbosity’s sake and since we are going to solely be ingesting the Driver logs later. Nevertheless, the config file may also be discovered on employee nodes at /dwelling/ubuntu/databricks/spark/dbconf/log4j/executor/log4j.properties.
You might add to this script as wanted, or cat $LOG4J2_PATH to view the total contents of the unique file for simpler modifications.
Subsequent, we are going to add this init script to the Unity Catalog Quantity. For group, we are going to create a separate Quantity somewhat than reuse our uncooked logs quantity from earlier, and this may be achieved in Terraform like so:
It will create the Quantity and routinely add the init script to it.
However we nonetheless must configure our cluster to make use of this init script. Earlier, we used a Cluster Coverage to implement the Log Supply vacation spot, and we will do the identical sort of enforcement for this init script to make sure our Spark logs all the time have the structured JSON formatting. We are going to modify the sooner coverage JSON by including the next:
Once more, utilizing a hard and fast worth right here ensures the init script will all the time be set on the cluster.
Now, if we re-run our Spark code from earlier, we will see all the Driver Logs within the Log4j part are properly formatted as JSON!
Ingesting the logs
At this level, we’ve ditched fundamental print statements for structured logging, unified that with Spark’s logs, and routed our logs to a central Quantity. That is already helpful for shopping and downloading the log information utilizing the Catalog Explorer or Databricks CLI: databricks fs cp dbfs:/Volumes/watchtower/default/cluster_logs/cluster-logs/$CLUSTER_ID . –recursive.
Nevertheless, the true worth of this logging hub is seen after we ingest the logs to a Unity Catalog desk. This closes the loop and offers us a desk towards which we will write expressive queries, carry out aggregations, and even detect widespread efficiency points. All of this we’ll get to shortly!
Ingesting the logs is straightforward because of Lakeflow Declarative Pipelines, and we’ll make use of a medallion structure with Auto Loader to incrementally load the info.
Bronze Logs
The primary desk is just a bronze desk to load the uncooked driver log information, appending some extra columns such because the file title, measurement, path, and final modification time.
Utilizing Lakeflow Declarative Pipeline’s expectations (AWS | Azure | GCP), we additionally get native information high quality monitoring. We are going to see extra of those information high quality checks on the opposite tables.
Silver Logs
The following (silver) desk is extra essential; we want to parse every line of textual content from the logs, extracting data such because the log stage, log timestamp, cluster ID, and log supply (stdout/stderr/log4j).
Observe: though we’ve configured JSON logging as a lot as potential, we are going to all the time have a point of uncooked textual content in unstructured kind from different instruments launched at startup. Most of those will probably be in stdout, and our silver transformation demonstrates one method to preserve parsing versatile, by making an attempt to parse the message as JSON and falling again to regex solely when essential.
Compute IDs
The final desk in our pipeline is a materialized view constructed upon Databricks System Tables. It is going to retailer the compute IDs utilized by every job run and simplify future joins after we want to retrieve the job ID that produced sure logs. Observe {that a} single job could have a number of clusters, in addition to SQL duties that execute on a warehouse somewhat than a job cluster, thus the usefulness of precomputing this reference.
Deploying the Pipeline
The pipeline could be deployed by the UI, Terraform, or inside our asset bundle. We are going to use the asset bundle and supply the next useful resource YAML:
Analyze Logs with AI/BI Dashboard
Lastly, we will question the log information throughout jobs, job runs, clusters, and workspaces. Because of the optimizations of Unity Catalog managed tables, these queries may even be quick and scalable. Let’s see a few examples.
High N Errors
This question finds the commonest errors encountered, serving to to prioritize and enhance error dealing with. It may also be a helpful indicator for writing runbooks that cowl the commonest points.
High N Jobs by Errors
This question ranks jobs by the variety of errors noticed, serving to to seek out essentially the most problematic jobs.
AI/BI Dashboard
If we put these queries right into a Databricks AI/BI dashboard, we now have a central interface to look and filter all logs, detect widespread points, and troubleshoot.
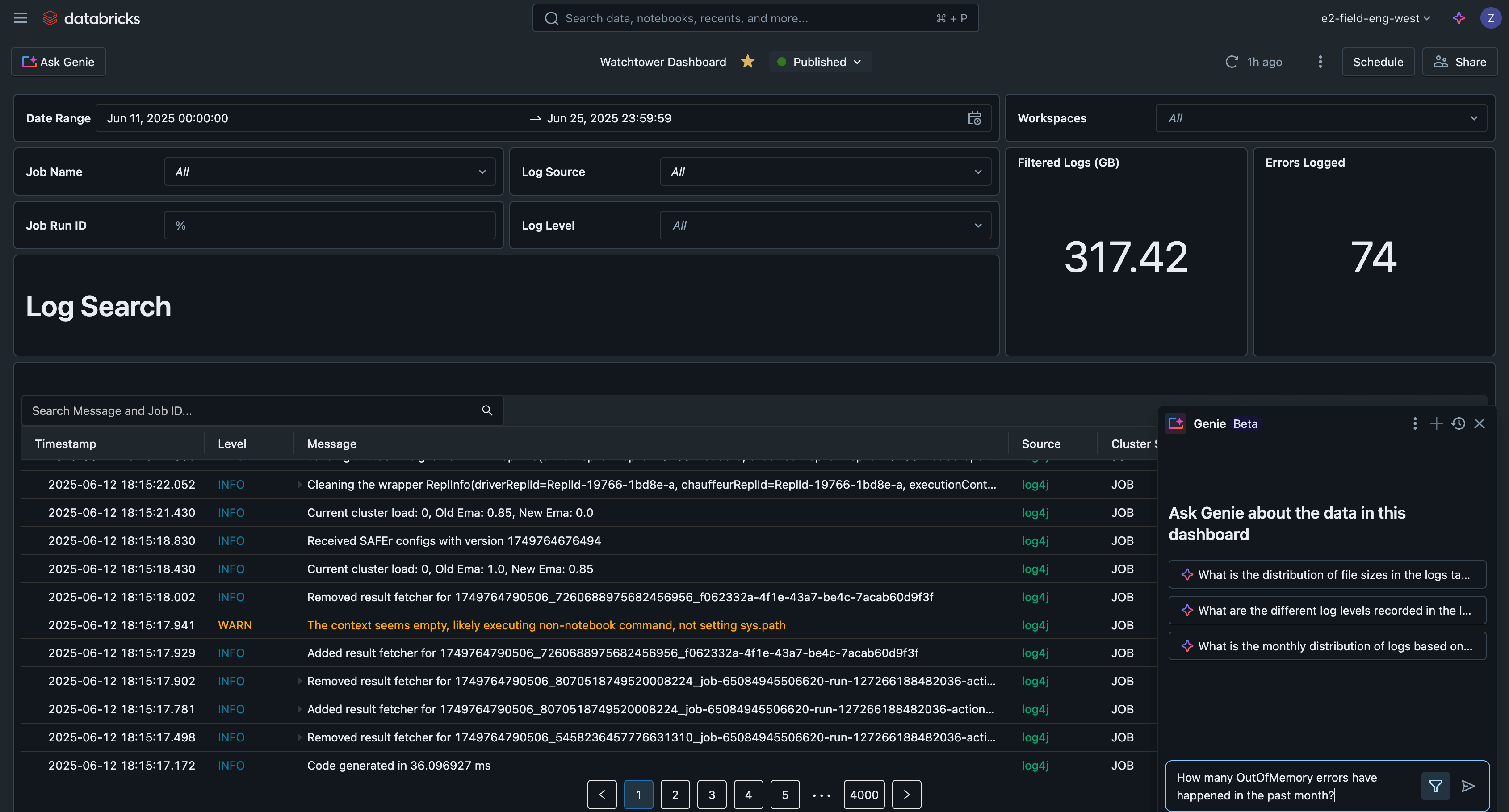
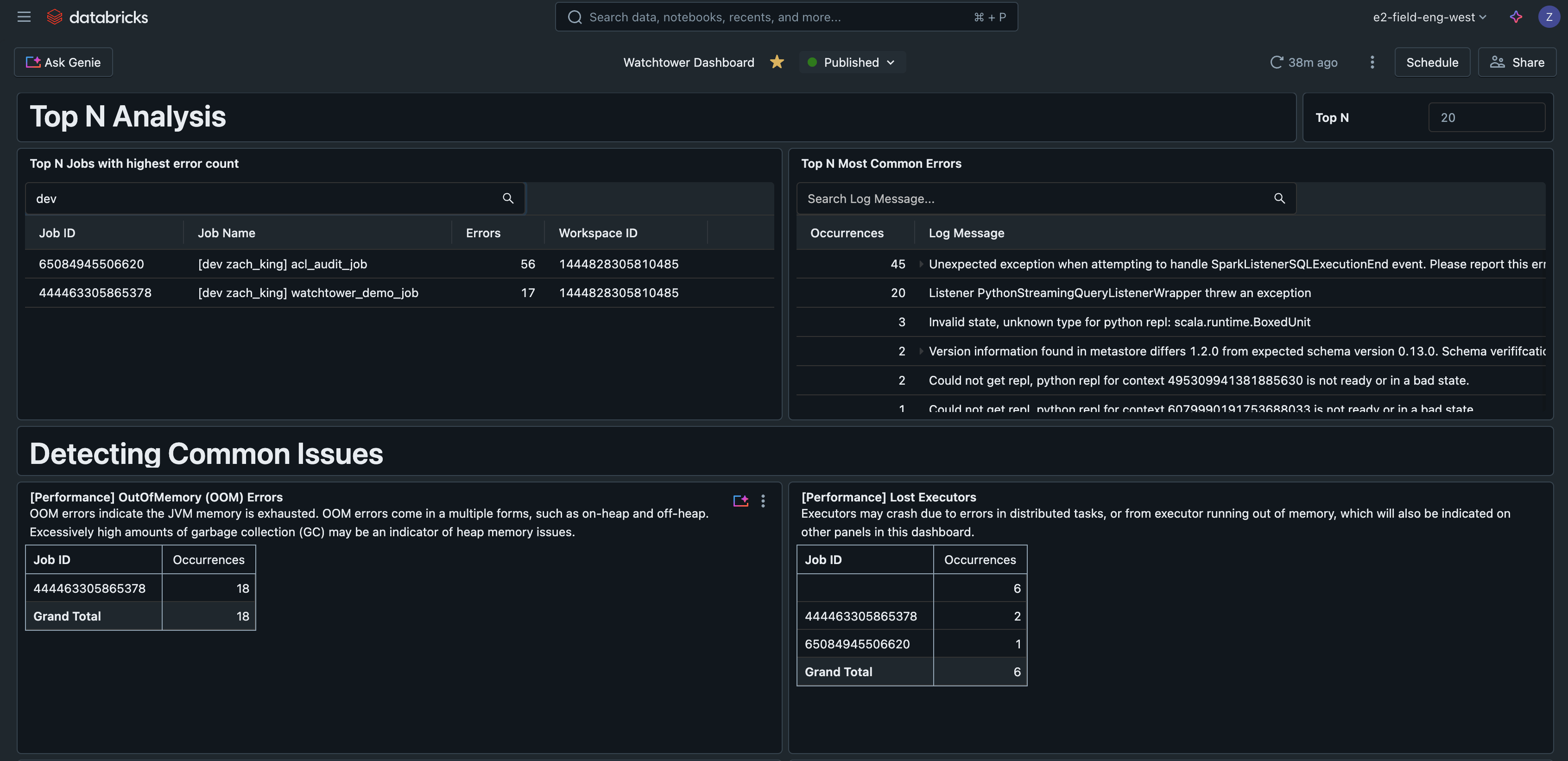
This instance AI/BI dashboard is obtainable together with all different code for this answer on GitHub.
Actual-World Situations
As we’ve demonstrated within the reference dashboard, there are lots of sensible use-cases {that a} logging answer like this helps, corresponding to:
Search logs throughout all runs for a single job
Search logs throughout all jobs
Analyzing logs for the commonest errors
Discover jobs with the best variety of errors
Monitoring for efficiency points or warnings:
Detecting PII in logs
In a sensible situation, practitioners are manually leaping round from one job run to the following to make sense of errors, and have no idea easy methods to prioritize alerts. By not solely establishing strong logs but additionally a regular desk to retailer them, practitioners can merely question the logs for the commonest error to be prioritized. Say there’s 1 failed job run resulting from an OutOfMemory error, whereas there are 10 failed jobs resulting from a sudden permission error when SELECT was unintentionally revoked from the service principal; your on-call staff is often fatigued by the surge of alerts, however now is ready to shortly understand the permission error is the next precedence and begins working to resolve the problem in an effort to restore the ten jobs.
Equally, practitioners usually must test logs for a number of runs of the identical job to make comparisons. An actual-world instance is correlating timestamps of a selected log message from every batch run of the job, with one other metric or graph (i.e., when “batch accomplished” was logged vs. a graph of request throughput on an API that you just known as). Ingesting the logs simplifies this, so we will question the desk and filter to the job ID, and optionally a listing of job run IDs, without having to click on into every run one by one.
Operational Issues
Cluster Logs are delivered each 5 minutes and gzipped hourly in your chosen vacation spot.
Bear in mind to make use of Unity Catalog-managed tables with Predictive Optimization and Liquid Clustering to get the very best efficiency on tables.
Uncooked logs don’t have to be saved indefinitely, which is the default habits when cluster log supply is used. In our Declarative Pipelines pipeline, use the Auto Loader possibility cloudFiles.cleanSource to delete information after a specified retention interval, additionally outlined as cloudFiles.cleanSource.retentionDuration. You may additionally use cloud storage lifecycle guidelines.
Executor logs may also be configured and ingested, however they’re usually not wanted as most errors are propagated to the driving force anyway.
Contemplate including Databricks SQL Alerts (AWS | Azure | GCP) for automated alerting primarily based on the ingested logs desk.
Lakeflow Declarative Pipelines have their very own occasion logs, which you’ll use to watch and examine pipeline exercise. This occasion log may also be written to Unity Catalog.
Integrating and Jobs to be achieved
Clients may additionally want to combine their logs with fashionable logging instruments corresponding to Loki, Logstash, or AWS CloudWatch. Whereas every has their very own authentication, configuration, and connectivity necessities, these would all observe a really comparable sample utilizing the cluster init script to configure and oftentimes run a log-forwarding agent.
Key Takeaways
To recap, the important thing classes are:
Use standardized logging frameworks, not print statements, in manufacturing.
Use cluster-scoped init scripts to customise the Log4j config.
Configure cluster log supply to centralize logs.
Use Unity Catalog managed tables with Predictive Optimization and Liquid Clustering for the very best desk efficiency.
Databricks lets you ingest and enrich logs for larger evaluation.
Subsequent Steps
Begin productionizing your logs at this time by testing the GitHub repo for this full answer right here: https://github.com/databricks-industry-solutions/watchtower!
Databricks Supply Options Architects (DSAs) speed up Knowledge and AI initiatives throughout organizations. They supply architectural management, optimize platforms for price and efficiency, improve developer expertise, and drive profitable challenge execution. DSAs bridge the hole between preliminary deployment and production-grade options, working carefully with numerous groups, together with information engineering, technical leads, executives, and different stakeholders to make sure tailor-made options and quicker time to worth. To learn from a customized execution plan, strategic steerage, and assist all through your information and AI journey from a DSA, please contact your Databricks Account Staff.

{kind=link}
I love how you write—it’s like having a conversation with a good friend. Can’t wait to read more!This post pulled me in from the very first sentence. You have such a unique voice!Seriously, every time I think I’ll just skim through, I end up reading every word. Keep it up!Your posts always leave me thinking… and wanting more. This one was no exception!Such a smooth and engaging read—your writing flows effortlessly. Big fan here!Every time I read your work, I feel like I’m right there with you. Beautifully written!You have a real talent for storytelling. I couldn’t stop reading once I started.The way you express your thoughts is so natural and compelling. I’ll definitely be back for more!Wow—your writing is so vivid and alive. It’s hard not to get hooked!You really know how to connect with your readers. Your words resonate long after I finish reading.