


As fashionable knowledge architectures increase, Apache Iceberg has change into a extensively well-liked open desk format, offering ACID transactions, time journey, and schema evolution. In desk format v2, Iceberg launched merge-on-read, bettering delete and replace dealing with by way of positional delete information. These information enhance write efficiency however can decelerate reads when not compacted, since Iceberg should merge them throughout question execution to return the newest snapshot. Iceberg v3 enhances merge efficiency throughout reads by changing positional delete information with deletion vectors for dealing with row-level deletes in Merge-on-Learn (MoR) tables. This transformation deprecates the usage of positional delete information in v3, which marked particular row positions as deleted, in favor of the extra environment friendly deletion vectors.
On this submit, we evaluate and consider the efficiency of the brand new binary deletion vectors in Iceberg v3 with respect to conventional place delete information of Iceberg v2 utilizing Amazon EMR model 7.10.0 with Apache Spark 3.5.5. We offer insights into the sensible impacts of those superior row-level delete mechanisms on knowledge administration effectivity and efficiency.
Understanding binary deletion vectors and Puffin information
Binary deletion vectors saved in Puffin information use compressed bitmaps to effectively signify which rows have been deleted inside an information file. In distinction, earlier Iceberg variations (v2) relied on positional delete information—Parquet information that enumerated rows to delete by file and place. This older strategy resulted in lots of small delete information, which positioned a heavy burden on question engines because of quite a few file reads and dear in-memory conversions. Puffin information cut back this overhead by compactly encoding deletions, bettering question efficiency and useful resource utilization.
Iceberg v3 improves this within the following elements:
Lowered I/O – Fewer small delete information decrease metadata overhead by introducing deletion vectors—compressed bitmaps that effectively signify deleted rows. These vectors are saved persistently in Puffin information, a compact binary format optimized for low-latency entry.
Question efficiency – Bitmap-based deletion vectors allow sooner scan filtering by permitting a number of vectors to be saved in a single Puffin file. This reduces metadata and file rely overhead whereas preserving file-level granularity for environment friendly reads. The design helps steady merging of deletion vectors, selling ongoing compaction that maintains secure question efficiency and reduces fragmentation over time. It removes the trade-off between partition-level and file-level delete granularity seen in v2, enabling constantly quick reads even in heavy-update situations.
Storage effectivity – Iceberg v3 makes use of a compressed binary format as an alternative of verbose Parquet positioning. Engines keep a single deletion vector per knowledge file at write time, enabling higher compaction and constant question efficiency.
Answer overview
To discover the efficiency traits of delete operations in Iceberg v2 and v3, we use PySpark to run our comparability exams specializing in delete operation runtime and delete file measurement. This implementation helps us successfully benchmark and evaluate the deletion mechanisms between Iceberg v2’s position-delete information utilizing Parquet and v3’s newer Puffin-based deletion vectors.
Our answer demonstrates the right way to configure Spark with the AWS Glue Knowledge Catalog and Iceberg, create tables, and run delete operations programmatically. We first create Iceberg tables with format variations 2 and three, insert 10,000 rows, then carry out delete operations on a spread of file IDs. We additionally carry out desk compaction after which measure delete operation runtime and measurement and rely of related delete information.
In Iceberg v3, deleting rows introduces binary deletion vectors saved in Puffin information (compact binary sidecar information). These permit extra environment friendly question planning and sooner learn efficiency by consolidating deletes and avoiding massive numbers of small information.
For this check, the Spark job was submitted by SSH’ing into the EMR cluster and utilizing spark-submit straight from the shell, with the required Iceberg JAR file being referenced straight from the Amazon Easy Storage Service (Amazon S3) bucket within the submission command. When operating the job, be sure you present your S3 bucket identify. See the next code:
spark-submit –jars s3://< S3-BUCKET-NAME >/iceberg/jars/iceberg-spark-runtime-3.5_2.12-1.9.2.jar v3_deletion_vector_test.py
Conditions
To comply with together with this submit, you will need to have the next stipulations:
Amazon EMR on Amazon EC2 with model 7.10.0 built-in with the Glue Knowledge Catalog, which incorporates Spark 3.5.5.
The Iceberg 1.9.2 JAR file from the official Iceberg documentation, which incorporates necessary deletion vector enhancements reminiscent of v2 to v3 rewrites and dangling deletion vector detection. Optionally, you should use the default Iceberg 1.8.1-amzn-0 bundled with Amazon EMR 7.10 if these Iceberg 1.9.x enhancements will not be required.
An S3 bucket to retailer Iceberg knowledge.
An AWS Identification and Entry administration (IAM) function for Amazon EMR configured with the mandatory permissions.
The upcoming Amazon EMR 7.11 will ship with Iceberg 1.9.1-amzn-1, which incorporates deletion vector enhancements reminiscent of v2 to v3 rewrites and dangling deletion vector detection. This implies you not must manually obtain or add the Iceberg JAR file, as a result of it is going to be included and managed natively by Amazon EMR.
Code walkthrough
The next PySpark script demonstrates the right way to create, write, compact, and delete data in Iceberg tables with two completely different format variations (v2 and v3) utilizing the Glue Knowledge Catalog because the metastore. The principle objective is to check each write and browse efficiency, together with storage traits (delete file format and measurement) between Iceberg format variations 2 and three.
The code performs the next capabilities:
Creates a SparkSession configured to make use of Iceberg with Glue Knowledge Catalog integration.
Creates an artificial dataset simulating person data:
Makes use of a hard and fast random seed (42) to offer constant knowledge technology
Creates equivalent datasets for each v2 and v3 tables for truthful comparability
Defines the operate test_read_performance(table_name) to carry out the next actions:
Measure full desk scan efficiency
Measure filtered learn efficiency (with WHERE clause)
Observe file counts for each operations
Defines the operate test_iceberg_table(model, test_df) to carry out the next actions:
Create or use an Iceberg desk for the desired format model
Append knowledge to the Iceberg desk
Set off Iceberg’s knowledge compaction utilizing a system process
Delete rows with IDs between 1000–1099
Acquire statistics about inserted knowledge information and delete-related information
Measure and file learn efficiency metrics
Observe operation timing for inserts, deletes, and reads
Defines a operate to print a complete comparative report together with the next data:
Delete operation efficiency
Learn efficiency (each full desk and filtered)
Delete file traits (codecs, counts, sizes)
Efficiency enhancements as percentages
Storage effectivity metrics
Orchestrate the primary execution movement:
Create a single dataset to make sure equivalent knowledge for each variations
Clear up present tables for contemporary testing
Run exams for Iceberg format model 2 and model 3
Output an in depth comparability report
Deal with exceptions and shut down the Spark session
See the next code:
from pyspark.sql import SparkSession
from pyspark.sql.sorts import StructType, StructField, IntegerType, StringType
from pyspark.sql import capabilities as F
import time
import random
import logging
from pyspark.sql.utils import AnalysisException
# Logging
logging.basicConfig(degree=logging.INFO, format=”%(message)s”)
logger = logging.getLogger(__name__)
# Constants
ROWS_COUNT = 10000
DELETE_RANGE_START = 1000
DELETE_RANGE_END = 1099
SAMPLE_NAMES = (“Alice”, “Bob”, “Charlie”, “Diana”,
“Eve”, “Frank”, “Grace”, “Henry”, “Ivy”, “Jack”)
# Spark Session
spark = (
SparkSession.builder
.appName(“IcebergWithGlueCatalog”)
.config(“spark.sql.extensions”, “org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions”)
.config(“spark.sql.catalog.glue_catalog”, “org.apache.iceberg.spark.SparkCatalog”)
.config(“spark.sql.catalog.glue_catalog.catalog-impl”, “org.apache.iceberg.aws.glue.GlueCatalog”)
.config(“spark.sql.catalog.glue_catalog.warehouse”, “s3:///weblog/glue/”)
.config(“spark.sql.catalog.glue_catalog.io-impl”, “org.apache.iceberg.aws.s3.S3FileIO”)
.getOrCreate()
)
spark.sql(“CREATE DATABASE IF NOT EXISTS glue_catalog.weblog”)
def create_dataset(num_rows=ROWS_COUNT):
# Set a hard and fast seed for reproducibility
random.seed(42)
knowledge = ((i,
random.selection(SAMPLE_NAMES) + str(i),
random.randint(18, 80))
for i in vary(1, num_rows + 1))
schema = StructType((
StructField(“id”, IntegerType(), False),
StructField(“identify”, StringType(), True),
StructField(“age”, IntegerType(), True)
))
df = spark.createDataFrame(knowledge, schema)
df = df.withColumn(“created_at”, F.current_timestamp())
return df
def test_read_performance(table_name):
“””Check learn efficiency of the desk”””
start_time = time.time()
rely = spark.sql(f”SELECT COUNT(*) FROM glue_catalog.weblog.{table_name}”).gather()(0)(0)
read_time = time.time() – start_time
# Check filtered learn efficiency
start_time = time.time()
filtered_count = spark.sql(f”””
SELECT COUNT(*)
FROM glue_catalog.weblog.{table_name}
WHERE age > 30
“””).gather()(0)(0)
filtered_read_time = time.time() – start_time
return read_time, filtered_read_time, rely, filtered_count
def test_iceberg_table(model, test_df):
attempt:
table_name = f”iceberg_table_v{model}”
logger.information(f”n=== TESTING ICEBERG V{model} ===”)
spark.sql(f”””
CREATE TABLE IF NOT EXISTS glue_catalog.weblog.{table_name} (
id int,
identify string,
age int,
created_at timestamp
) USING iceberg
TBLPROPERTIES (
‘format-version’='{model}’,
‘write.delete.mode’=’merge-on-read’
)
“””)
start_time = time.time()
test_df.writeTo(f”glue_catalog.weblog.{table_name}”).append()
insert_time = time.time() – start_time
logger.information(“Compaction…”)
spark.sql(
f”CALL glue_catalog.system.rewrite_data_files(‘glue_catalog.weblog.{table_name}’)”)
start_time = time.time()
spark.sql(f”””
DELETE FROM glue_catalog.weblog.{table_name}
WHERE id BETWEEN {DELETE_RANGE_START} AND {DELETE_RANGE_END}
“””)
delete_time = time.time() – start_time
files_df = spark.sql(
f”SELECT COUNT(*) as data_files FROM glue_catalog.weblog.{table_name}.information”)
delete_files_df = spark.sql(f”””
SELECT COUNT(*) as delete_files,
file_format,
SUM(file_size_in_bytes) as total_size
FROM glue_catalog.weblog.{table_name}.delete_files
GROUP BY file_format
“””)
data_files = files_df.gather()(0)(‘data_files’)
delete_stats = delete_files_df.gather()
# Add learn efficiency testing
logger.information(“nTesting learn efficiency…”)
read_time, filtered_read_time, total_count, filtered_count = test_read_performance(table_name)
logger.information(f”Insert time: {insert_time:.3f}s”)
logger.information(f”Delete time: {delete_time:.3f}s”)
logger.information(f”Full desk learn time: {read_time:.3f}s”)
logger.information(f”Filtered learn time: {filtered_read_time:.3f}s”)
logger.information(f”Knowledge information: {data_files}”)
logger.information(f”Whole data: {total_count}”)
logger.information(f”Filtered data: {filtered_count}”)
if len(delete_stats) > 0:
stats = delete_stats(0)
logger.information(f”Delete information: {stats.delete_files}”)
logger.information(f”Delete format: {stats.file_format}”)
logger.information(f”Delete information measurement: {stats.total_size} bytes”)
return delete_time, stats.total_size, stats.file_format, read_time, filtered_read_time
else:
logger.information(“No delete information discovered”)
return delete_time, 0, “N/A”, read_time, filtered_read_time
besides AnalysisException as e:
logger.error(f”SQL Error: {str(e)}”)
elevate
besides Exception as e:
logger.error(f”Error: {str(e)}”)
elevate
def print_comparison_results(v2_results, v3_results):
v2_delete_time, v2_size, v2_format, v2_read_time, v2_filtered_read_time = v2_results
v3_delete_time, v3_size, v3_format, v3_read_time, v3_filtered_read_time = v3_results
logger.information(“n=== PERFORMANCE COMPARISON ===”)
logger.information(f”v2 delete time: {v2_delete_time:.3f}s”)
logger.information(f”v3 delete time: {v3_delete_time:.3f}s”)
if v2_delete_time > 0:
enchancment = ((v2_delete_time – v3_delete_time) / v2_delete_time) * 100
logger.information(f”v3 Delete efficiency enchancment: {enchancment:.1f}%”)
logger.information(“n=== READ PERFORMANCE COMPARISON ===”)
logger.information(f”v2 full desk learn time: {v2_read_time:.3f}s”)
logger.information(f”v3 full desk learn time: {v3_read_time:.3f}s”)
logger.information(f”v2 filtered learn time: {v2_filtered_read_time:.3f}s”)
logger.information(f”v3 filtered learn time: {v3_filtered_read_time:.3f}s”)
if v2_read_time > 0:
read_improvement = ((v2_read_time – v3_read_time) / v2_read_time) * 100
logger.information(f”v3 Learn efficiency enchancment: {read_improvement:.1f}%”)
if v2_filtered_read_time > 0:
filtered_improvement = ((v2_filtered_read_time – v3_filtered_read_time) / v2_filtered_read_time) * 100
logger.information(f”v3 Filtered learn efficiency enchancment: {filtered_improvement:.1f}%”)
logger.information(“n=== DELETE FILE COMPARISON ===”)
logger.information(f”v2 delete format: {v2_format}”)
logger.information(f”v2 delete measurement: {v2_size} bytes”)
logger.information(f”v3 delete format: {v3_format}”)
logger.information(f”v3 delete measurement: {v3_size} bytes”)
if v2_size > 0:
size_reduction = ((v2_size – v3_size) / v2_size) * 100
logger.information(f”v3 measurement discount: {size_reduction:.1f}%”)
# Most important
attempt:
# Create dataset as soon as and reuse for each variations
test_dataset = create_dataset()
# Drop present tables in the event that they exist
spark.sql(“DROP TABLE IF EXISTS glue_catalog.weblog.iceberg_table_v2”)
spark.sql(“DROP TABLE IF EXISTS glue_catalog.weblog.iceberg_table_v3”)
# Check each variations with the identical dataset
v2_results = test_iceberg_table(2, test_dataset)
v3_results = test_iceberg_table(3, test_dataset)
print_comparison_results(v2_results, v3_results)
lastly:
spark.cease()
Outcomes abstract
The output generated by the code contains the outcomes abstract part that reveals a number of key comparisons, as proven within the following screenshot. For delete operations, Iceberg v3 makes use of the Puffin file format in comparison with Parquet in v2, leading to important enhancements. The delete operation time decreased from 3.126 seconds in v2 to 1.407 seconds in v3, attaining a 55.0% efficiency enchancment. Moreover, the delete file measurement was diminished from 1801 bytes utilizing Parquet in v2 to 475 bytes utilizing Puffin in v3, representing a 73.6% discount in storage overhead. Learn operations additionally noticed notable enhancements, with full desk reads 28.5% sooner and filtered reads 23% sooner in v3. These enhancements exhibit the effectivity beneficial properties from v3’s implementation of binary deletion vectors by way of the Puffin format.
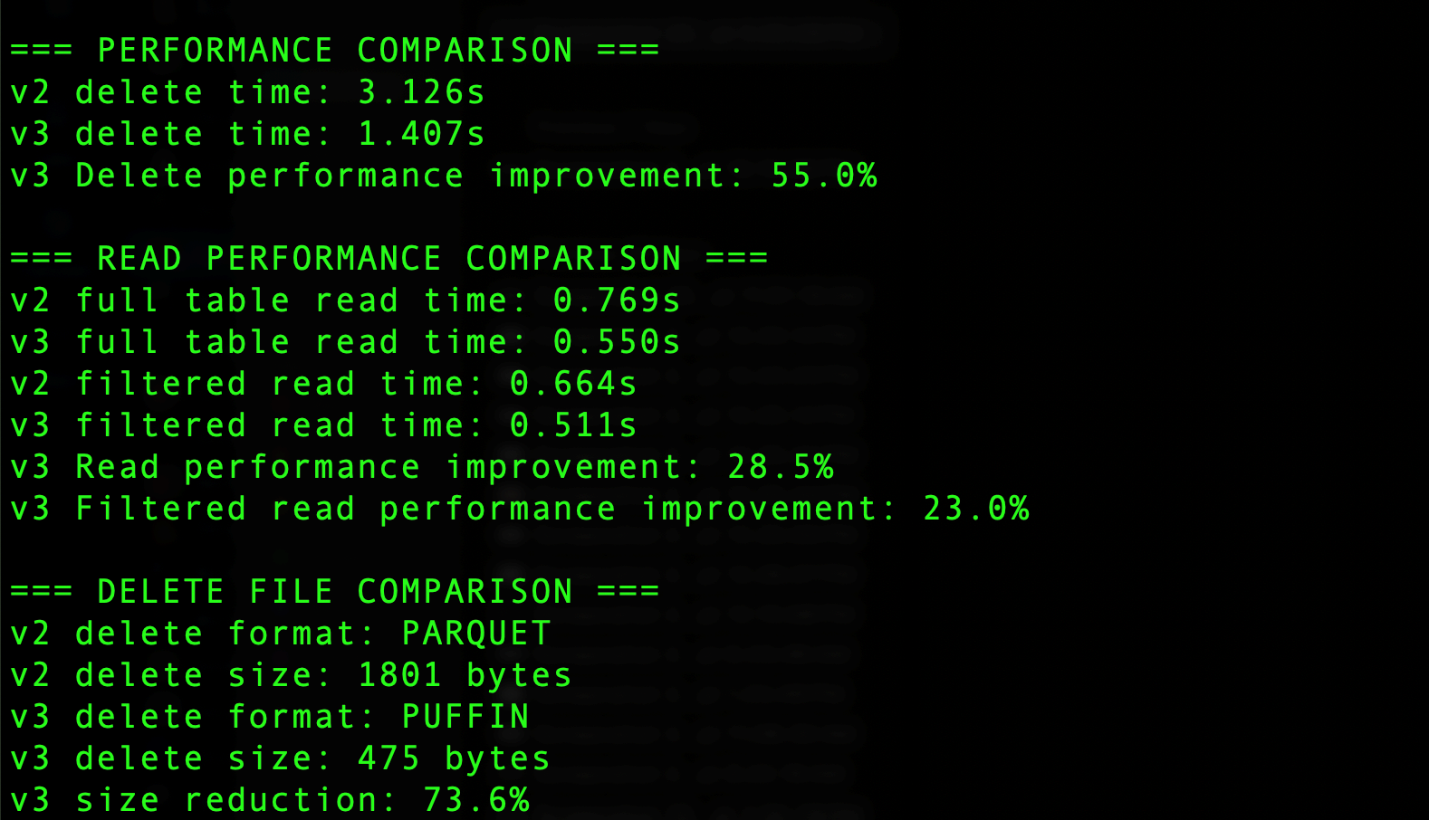
The precise measured efficiency and storage enhancements depend upon workload and surroundings and would possibly differ from the previous instance.
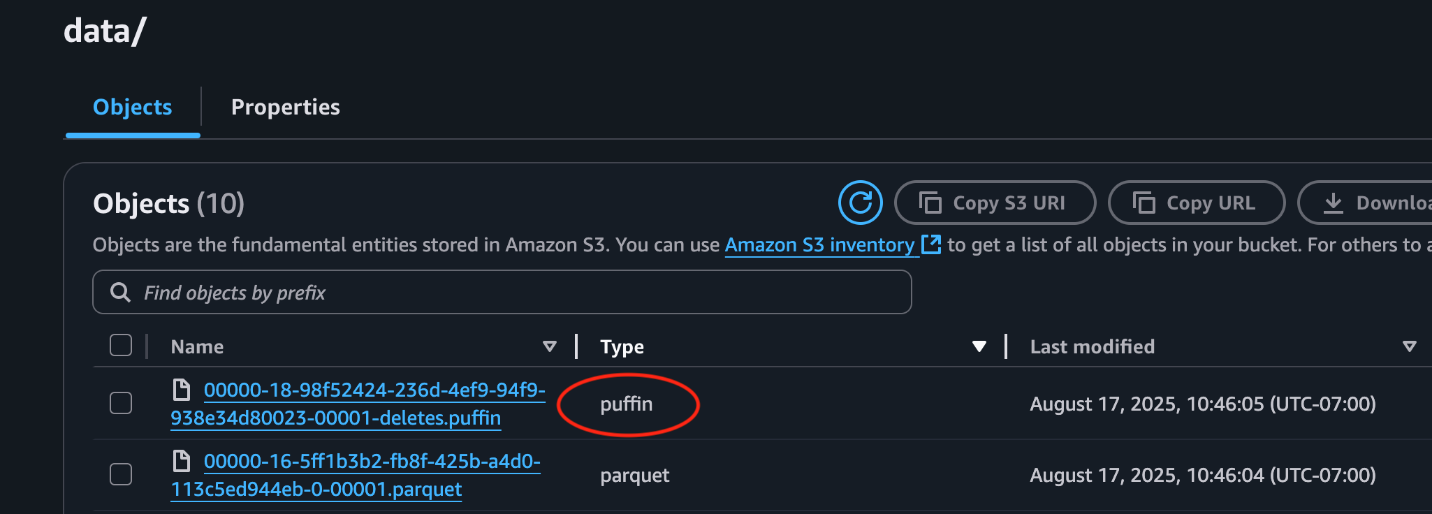
This following screenshot from the S3 bucket demonstrates a Puffin delete file saved alongside knowledge information.
Clear up
After you end your exams, it’s necessary to scrub up your surroundings to keep away from pointless prices:
Drop the check tables you created to take away related knowledge out of your S3 bucket and forestall ongoing storage costs.
Delete any non permanent knowledge left within the S3 bucket used for Iceberg knowledge.
Delete the EMR cluster to cease billing for operating compute assets.
Cleansing up assets promptly helps keep cost-efficiency and useful resource hygiene in your AWS surroundings.
Issues
Iceberg options are launched by way of a phased course of: first within the specification, then within the core library, and eventually in engine implementations. Deletion vector assist is at the moment out there within the specification and core library, with Spark being the one supported engine. We validated this functionality on Amazon EMR 7.10 with Spark 3.5.5.
Conclusion
Iceberg v3 introduces a major development in managing row-level deletes for merge-on-read operations by way of binary deletion vectors saved in compact Puffin information. Our efficiency exams, performed with Iceberg 1.9.2 on Amazon EMR 7.10.0 and EMR Spark 3.5.5, present clear enhancements in each delete operation velocity and browse efficiency, together with a substantial discount in delete file storage in comparison with Iceberg v2’s positional delete Parquet information. For extra details about deletion vectors, discuss with Iceberg v3 deletion vectors.
In regards to the authors

Arun Shanmugam
Arun is a Senior Analytics Options Architect at AWS, with a give attention to constructing fashionable knowledge structure. He has been efficiently delivering scalable knowledge analytics options for purchasers throughout numerous industries. Exterior of labor, Arun is an avid outside fanatic who actively engages in CrossFit, street biking, and cricket.

Suthan Phillips
Suthan is a Senior Analytics Architect at AWS, the place he helps prospects design and optimize scalable, high-performance knowledge options that drive enterprise insights. He combines architectural steerage on system design and scalability with greatest practices to offer environment friendly, safe implementation throughout knowledge processing and expertise layers. Exterior of labor, Suthan enjoys swimming, mountain climbing, and exploring the Pacific Northwest.

Kinshuk Paharae
Kinshuk is head of product for knowledge processing, main product groups for AWS Glue, Amazon EMR, and Amazon Athena. He has been with AWS for over 5 years.

Linda O’Connor
Linda is a Seasoned Go-To-Market Chief with shut to a few a long time of expertise driving progress methods within the knowledge and analytics area. At AWS, she at the moment leads pan analytics initiatives together with lakehouse architectures, serving to prospects remodel their present landscapes by way of non-disruptive innovation. She beforehand served as World Vice President at a German software program firm for 25 years, the place she spearheaded Knowledge Warehousing and Large Knowledge portfolios, orchestrating profitable product launches and driving world market enlargement.
